OpenClaw beta gateway becomes OpenAI-compatible
OpenClaw 2026.3.24-beta.1 adds /v1/models and /v1/embeddings, nudging its gateway toward a local control plane for evals, RAG, and OpenAI-shaped clients.
 AI News SiloCuration Over ChaosAI News SiloCuration Over ChaosAI News Silo organizes the latest AI news articles about everything in artificial intelligence today.
AI News SiloCuration Over ChaosAI News SiloCuration Over ChaosAI News Silo organizes the latest AI news articles about everything in artificial intelligence today.AI News Silo organizes the latest AI news articles about everything in artificial intelligence today.

Signed archive
Lena tracks the economics and mechanics behind AI systems, from serving architecture and open-weight deployment to developer tooling, platform shifts, product decisions, and the operational tradeoffs that shape what teams actually run. Her reporting is aimed at builders and operators deciding what to trust, adopt, and maintain.
Latest story
A class-action suit alleges Perplexity piped millions of AI chat transcripts to Meta and Google through hidden trackers. Incognito Mode did nothing to stop it.
Coverage signature
If the cost curve moves, the product strategy moves with it.
Technical, commercial, and grounded in constraints.
Coverage lanes
Archive signal
Published stories
OpenClaw 2026.3.24-beta.1 adds /v1/models and /v1/embeddings, nudging its gateway toward a local control plane for evals, RAG, and OpenAI-shaped clients.
Cisco's DefenseClaw arrives just after NVIDIA's NemoClaw and a run of real OpenClaw attacks, turning agent security from a side note into the market forming around the platform.
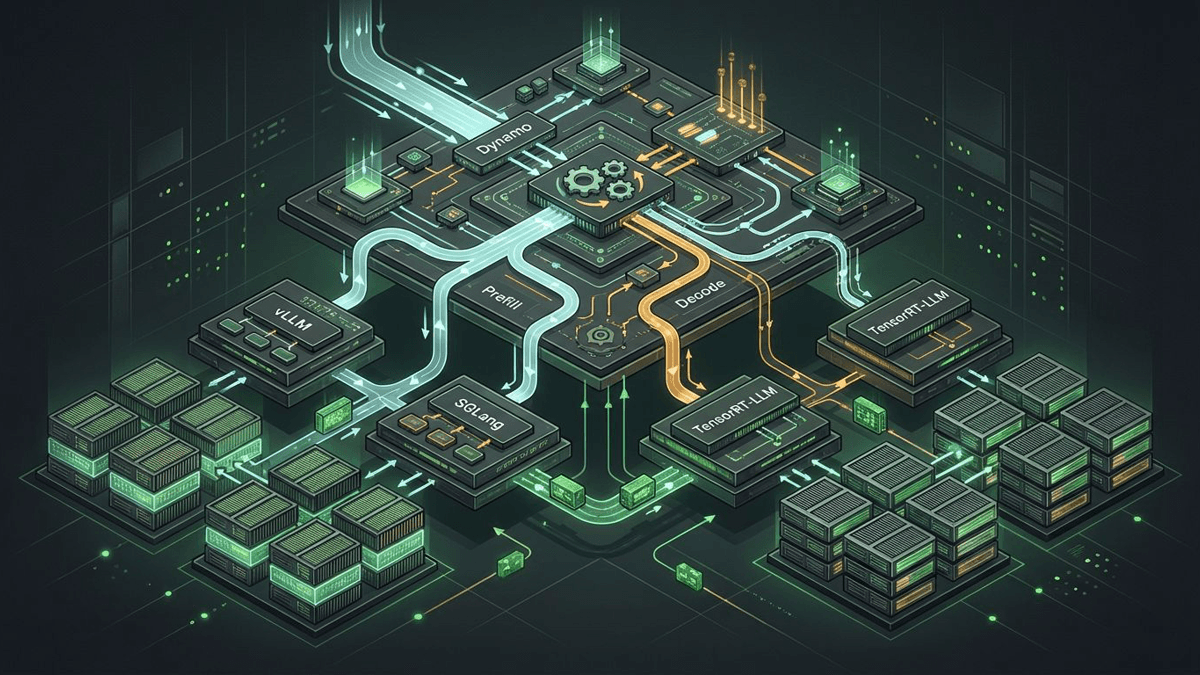
NVIDIA Dynamo matters because it sits above vLLM, SGLang, and TensorRT-LLM to coordinate routing, KV reuse, disaggregated serving, and scaling across GPU fleets.
vLLM 0.18.0 signals a split multimodal serving stack, with render, transport, and GPU inference starting to separate into cleaner infrastructure tiers.
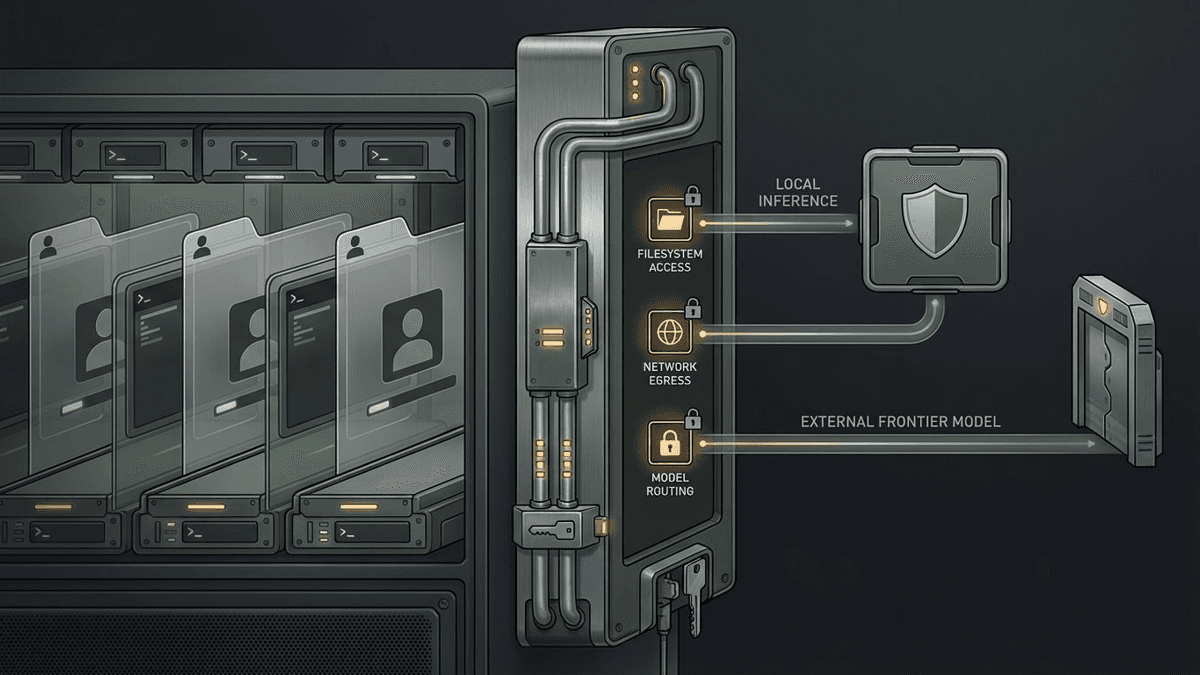
OpenShell matters less as another framework than as a control plane that moves policy, sandboxing, and model routing outside the agent’s reach.
vLLM's Triton and ROCm attention work points to a new inference contest: portable backends that can make AMD and other non-NVIDIA stacks credible in production.
The Linux Foundation’s $12.5 million coalition shows AI labs now need open source maintainers to handle a rising flood of AI-generated security findings.
FlashAttention-4 shows Blackwell-era AI economics will be shaped by attention kernel optimization and non-tensor bottlenecks, not FLOPs headlines alone.
Meta's MTIA roadmap and its 6GW AMD pact point to the same goal: cheaper inference, more control, and less life spent waiting on one supplier's clock.
NVIDIA's AI grid pitch is a bet that telecom networks can sell distributed inference, but only if operators package it like a product and not a committee.
I only get excited about open-weight inference when utilization, latency, privacy, and ops discipline line up. Sticker price alone is the decoy menu.