vLLM 0.18.0 points to a split multimodal stack
vLLM 0.18.0 signals a split multimodal serving stack, with render, transport, and GPU inference starting to separate into cleaner infrastructure tiers.

 ainewssilo.com
ainewssilo.comvLLM's most interesting 0.18.0 move is not one faster endpoint. It is the idea that multimodal serving can be split into cleaner tiers.
I think vLLM 0.18.0 matters because it starts to cut the serving box into cleaner pieces.
The release notes are easy to summarize: gRPC support, a new vllm launch render mode, and scheduler gains for PD disaggregation all landed together. That is factual. It is also not the part I find interesting.
What I find interesting is the direction. vLLM is making it more practical to separate request rendering, transport, and GPU inference so they do not all have to live on the same machine or even inside the same process boundary. That does not mean every team needs a split-stack serving topology tomorrow. It does mean one of the most important open-source serving stacks is now exposing the seams operators actually need.
vLLM is starting to split the serving box in half
The gRPC addition is revealing for a reason that has nothing to do with protocol tribalism. The OpenAI-compatible server docs still make clear that HTTP remains a first-class way to run vLLM. The interesting part is in the gRPC PR: vllm serve gets a --grpc flag, but the actual servicer is lazy-imported from smg-grpc-servicer, with proto stubs coming from smg-grpc-proto.
That tells me transport is becoming more replaceable.

In a monolithic serving stack, every new interface tends to become a whole-platform commitment. Here, vLLM is moving the other way. Teams that want HTTP can keep HTTP. Teams that want RPC-style internal calls can add gRPC. The runtime is becoming less opinionated about the edge of the box.
Render serving takes expensive GPU babysitting off the table
The bigger move is vllm launch render. It is explicitly CPU-only, and it can handle request preprocessing without a GPU and without an inference engine: chat template rendering, tokenization, tool parsing, reasoning parsing, and input preparation.
That matters because modern multimodal requests carry a lot of baggage before generation even begins. vLLM's own multimodal inputs docs are a reminder that images, video frames, audio extraction, and media controls often have to be handled before the token loop ever starts.
I keep thinking about a restaurant again. You do not put the salad prep station inside the oven. GPUs are expensive. Shoving CPU-heavy media handling, request sanitation, and template rendering onto the same node as inference is often just an expensive way to make your accelerator babysit chores.
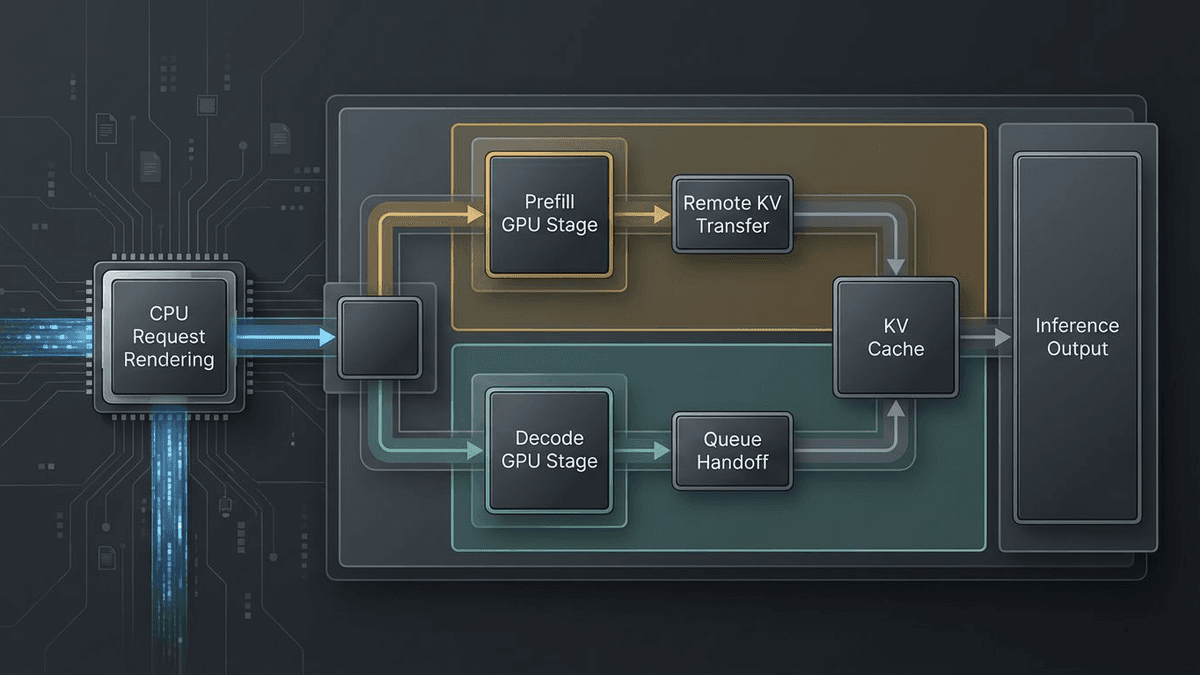
Once vLLM exposes a formal render tier, the architecture starts to look more sensible: prepare requests elsewhere, move them cleanly over the network, and spend GPU time on the part that actually needs the accelerator.
My read on where open-model serving is heading
The scheduler work around PD disaggregation reinforces the same direction. In the remote-KV scheduler PR, vLLM stops repeatedly popping and re-prepending blocked requests in the main queue and instead keeps a separate queue for remote KV waits, promoting requests when finished_recving fires. The author reports around 5% end-to-end improvement in that setup. Even if you discount the exact number, the priority is revealing: the team is investing in the control-plane pain of a split prefill/decode system.
Put the three changes together and the pattern gets hard to miss. One loosens transport. One peels preprocessing away from GPU inference. One smooths the rough edges of disaggregated serving. That is not a random grab bag. It is a stack getting more comfortable with being cut into layers.
I would not get romantic about it. Transport diversity is not adoption. CPU-only render serving is not an instant multimodal control plane. Disaggregated prefill still brings its own queueing, observability, and network headaches. But the direction makes sense, especially if you care about open-weight inference economics. The performance fight keeps moving into the plumbing around the model.
vLLM 0.18.0 does not finish that transition. I think it marks it. The serving stack is starting to split, and I would be surprised if it starts growing back together.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Release notes confirming the 2026-03-20 ship date and the three user-facing changes at the center of this piece: gRPC serving, GPU-less render serving, and PD-disaggregation scheduler gains.
Primary source for the new `vllm serve --grpc` flag, the optional `vllm[grpc]` install path, and the decision to move the servicer into a separately versioned package.
Primary source for the CPU-only render server that handles chat template rendering, tokenization, and request preprocessing without a GPU or inference engine.
Primary source for the scheduler changes that reduce queue churn around async remote KV loads in prefill/decode disaggregation.
Confirms the existing HTTP OpenAI-compatible serving path remains a first-class interface.
Grounds the article's claims about multimodal preprocessing complexity and the operational implications of separating media handling from GPU inference.

About the author
Lena Ortiz
Lena tracks the economics and mechanics behind AI systems, from serving architecture and open-weight deployment to developer tooling, platform shifts, product decisions, and the operational tradeoffs that shape what teams actually run. Her reporting is aimed at builders and operators deciding what to trust, adopt, and maintain.
- 24
- Apr 10, 2026
- Berlin
Archive signal
Reporting lens: Operating leverage beats ideological posturing.. Signature: If the cost curve moves, the product strategy moves with it.
Article details
- Category
- AI Infrastructure
- Last updated
- April 11, 2026
- Public sources
- 6 linked source notes
Byline
Covers the economics, tooling, and operating realities that shape how AI gets built, shipped, and run.



