NVIDIA Dynamo is the orchestration layer above vLLM
NVIDIA Dynamo matters because it sits above vLLM, SGLang, and TensorRT-LLM to coordinate routing, KV reuse, disaggregated serving, and scaling across GPU fleets.
 ainewssilo.com
ainewssilo.comNVIDIA Dynamo is most interesting when you stop reading it as a faster server and start reading it as the control layer above the servers.
I think NVIDIA Dynamo 1.0 matters because it is not really trying to be one more model server, and that is the smartest thing about it.
The inference market did not need another shiny endpoint wearing a cape. It did need a better answer to the ugly coordination problems that appear after you stop serving toy loads. NVIDIA's own README gives the cleanest explanation: Dynamo is "the orchestration layer above inference engines." That sentence is more useful than half the keynote copy.
If you are serving one model on one GPU, Dynamo is probably not your problem. If you are trying to reuse KV cache intelligently, separate prefill from decode, survive messy traffic, and keep latency from turning into a customer-facing embarrassment, Dynamo starts to look a lot more relevant.
Dynamo is not another model server, and that matters
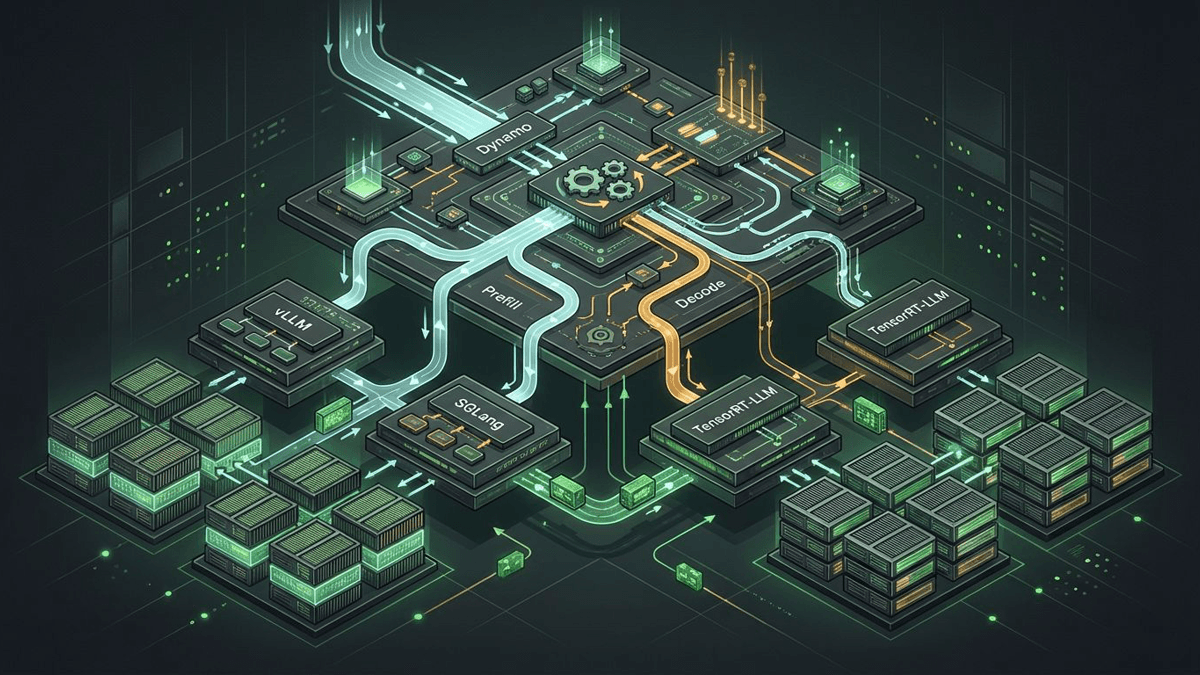
NVIDIA's architecture docs split the system into three planes: a request plane for request and response execution, a control plane for scaling and desired-state management, and a storage-and-events plane for KV visibility, transfer, and reuse. That is not the anatomy of a simple serving endpoint. It is the anatomy of a coordinator.
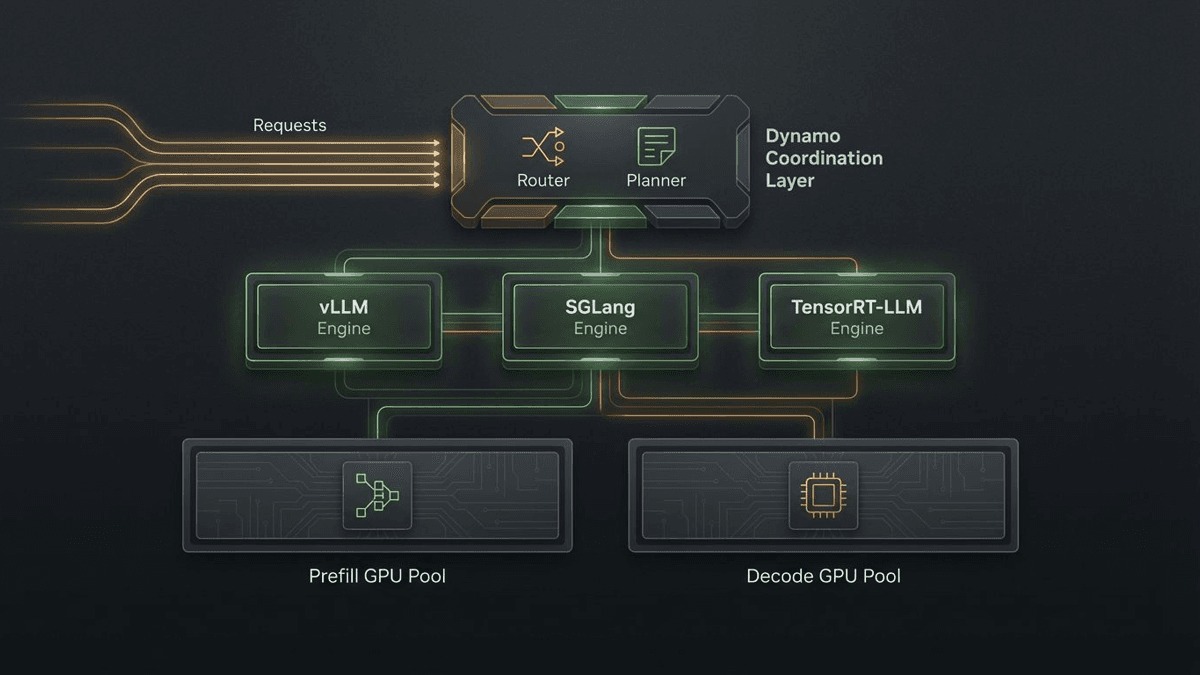
In that design, backend engines still do the actual serving work. Dynamo can sit above vLLM, SGLang, or TensorRT-LLM. The frontend accepts traffic, the router decides placement, prefill workers build prompt state, decode workers generate tokens, and KV events keep the cluster aware of reusable context. The planner reacts to load and latency targets while systems like KVBM and NIXL handle the deeply unsexy job of moving cache state around without wasting expensive memory tiers.
That is why the simple "Dynamo versus vLLM" framing misses the point. One is an engine. The other is trying to orchestrate a fleet of engines.
NVIDIA wants to orchestrate the messy middle of inference
The disaggregated-serving story makes this even clearer. NVIDIA spends a lot of time on prefill versus decode because they are different jobs with different bottlenecks. Prefill is compute-bound. Decode is memory-bound. Running both on the same resource pool is convenient, but it is also a good way to waste headroom once sequence lengths and concurrency get large.
Dynamo's answer is to split those phases into separate pools that can scale independently, then use a planner to decide when that split is actually worth the added transfer and coordination cost. I like that detail because disaggregation is not magic. It is air-traffic control. Splitting the runway only helps if somebody is actually managing the planes.
NVIDIA even includes Grove for topology-aware Kubernetes deployment because once inference becomes a multi-component, multi-node workload, "just launch the server" stops being an operating plan.
KV-aware routing is the whole pitch in one feature
The clearest proof of the thesis is KV-aware routing. Dynamo's docs and launch materials say the router tracks KV overlap across workers and places new requests based on both cache overlap and load. The goal is obvious: if useful context already lives somewhere, avoid paying the prefill bill again.
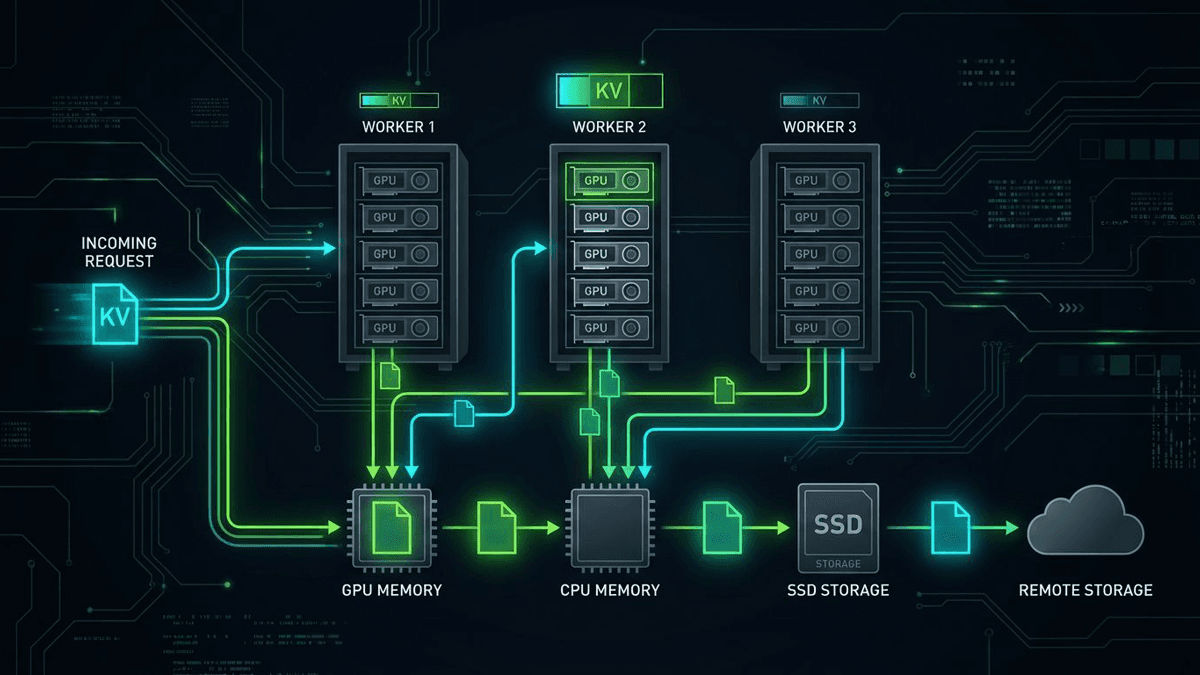
That can matter a lot in long-context and agentic workloads. Baseten's case study is the best external support in the source pack. It says KV-aware routing cut average time to first token by 50% and time per output token by 34% on a Qwen3 Coder workload, while also lowering tail latency on shadowed production traffic. That does not prove every NVIDIA benchmark deck. It does show the core idea is commercially real in the right workload shape.
The same goes for Dynamo's multi-tier KV story. KVBM is meant to manage reuse, eviction, and offload across GPU memory, CPU memory, SSD, and remote storage. That is not basic model serving. That is cache logistics for a serving cluster.
My take on the layer above the engine
I would still keep vendor skepticism fully stocked. NVIDIA's launch material is full of enormous performance claims, and those should be read as vendor framing, not gospel. But the docs-backed architectural story is strong enough without the loudest numbers. Dynamo is built around separate request, control, and state paths; it supports multiple serving engines; and it treats routing, scaling, failure handling, and KV movement as first-class product surfaces.
That is why I think Dynamo matters beyond NVIDIA itself. If this category works, more of the operational value in inference will move into the coordination layer above the engine. Backend choice will still matter, but less in isolation. The fight will move upward, just like it already has in vLLM's split-serving work and in the broader economics story around FlashAttention-4 and Blackwell.
The bottom line for me is simple: Dynamo is an attempt to own the messy middle of inference. That middle is where a lot of the money is about to live.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Official product page describing Dynamo as an open-source distributed inference framework with planner, router, KV management, NIXL, and Grove.
Launch architecture post explaining disaggregated serving, planner behavior, smart routing, and KV cache offload.
The clearest docs-backed explanation of Dynamo's request plane, control plane, and storage-events plane.
README states directly that Dynamo is the orchestration layer above inference engines rather than a replacement for them.
Third-party case study focused on KV-aware routing, with concrete latency and throughput claims from one deployment pattern.
Use cautiously for ecosystem adoption claims and NVIDIA's own framing of Dynamo as an operating system for AI factories.

About the author
Lena Ortiz
Lena tracks the economics and mechanics behind AI systems, from serving architecture and open-weight deployment to developer tooling, platform shifts, product decisions, and the operational tradeoffs that shape what teams actually run. Her reporting is aimed at builders and operators deciding what to trust, adopt, and maintain.
- 24
- Apr 10, 2026
- Berlin
Archive signal
Reporting lens: Operating leverage beats ideological posturing.. Signature: If the cost curve moves, the product strategy moves with it.
Article details
- Category
- AI Infrastructure
- Last updated
- April 11, 2026
- Lead illustration
- The pitch is not "here is one more model server." It is "here is the layer that coordinates the servers you already use."
- Public sources
- 6 linked source notes
Byline
Covers the economics, tooling, and operating realities that shape how AI gets built, shipped, and run.



