OpenAI audio models plug the missing agent voice layer
OpenAI next-generation audio models look less like a model drop and more like the missing voice layer for its agent stack, with better transcription, steerable TTS, and live voice-agent docs.
 ainewssilo.com
ainewssilo.comOpenAI did not just ship better audio models. It finally shipped enough voice plumbing that its agent platform can stop communicating through interpretive dance.
OpenAI's April 5 audio release looks, at first glance, like one more model announcement with some benchmark swagger attached. Read it next to the company's existing agent push, though, and the more interesting story appears.
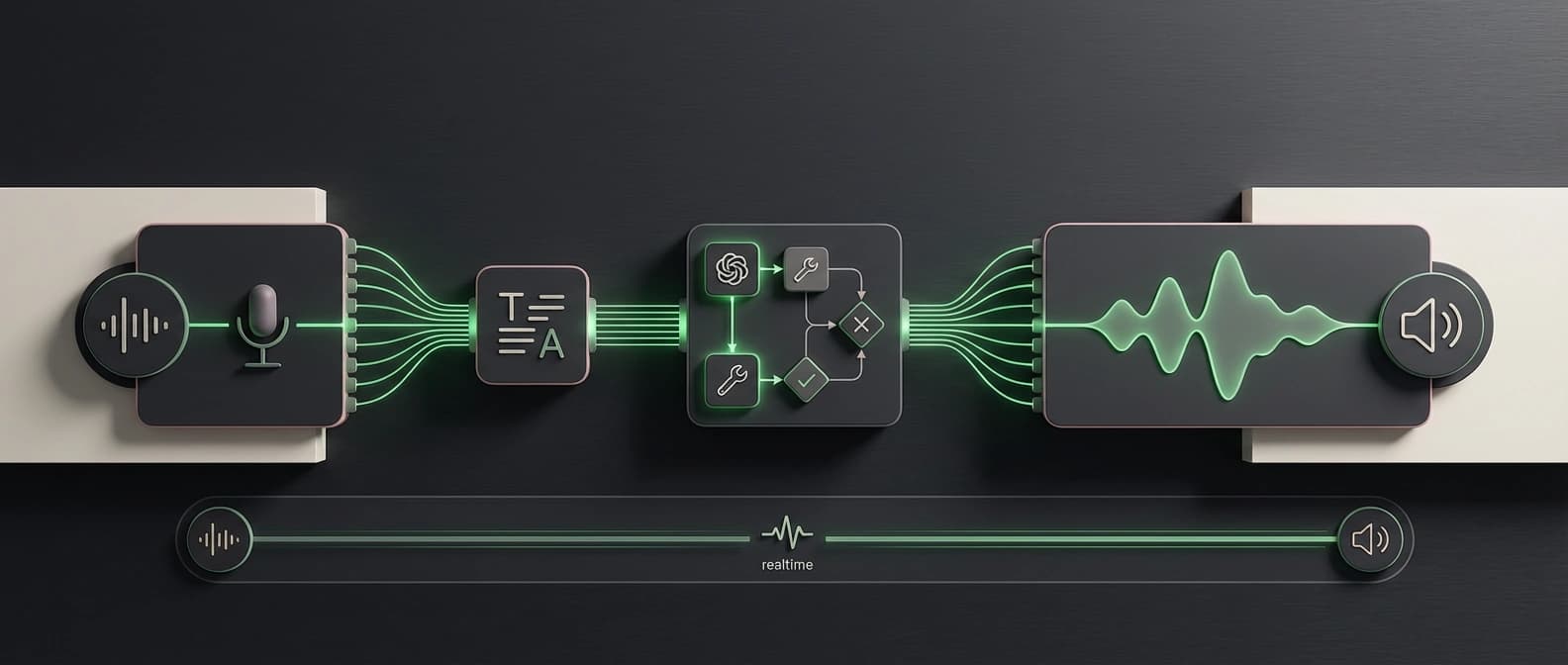
gpt-4o-transcribe, gpt-4o-mini-transcribe, and steerable gpt-4o-mini-tts are useful products. Paired with the live audio guides and the Agents SDK VoicePipeline quickstart, they do something OpenAI badly needed: they give the broader agent platform a practical voice layer.
OpenAI has spent months selling the brains, tools, tracing, and workflow scaffolding for agents. The ears and mouth were the awkward part. A text agent can look brilliant in a demo. A voice agent still has to hear the human, say something sensible back, and avoid sounding like a microwave reading a bedtime story.
Why OpenAI next-generation audio models matter to agents
OpenAI's release sitemap shows the launch page for "Introducing next-generation audio models in the API" with a lastmod of 2026-04-05T00:43:06.987Z. More important, the live docs line up with the release framing instead of leaving developers to assemble the rest of the stack from vibes and forum posts.
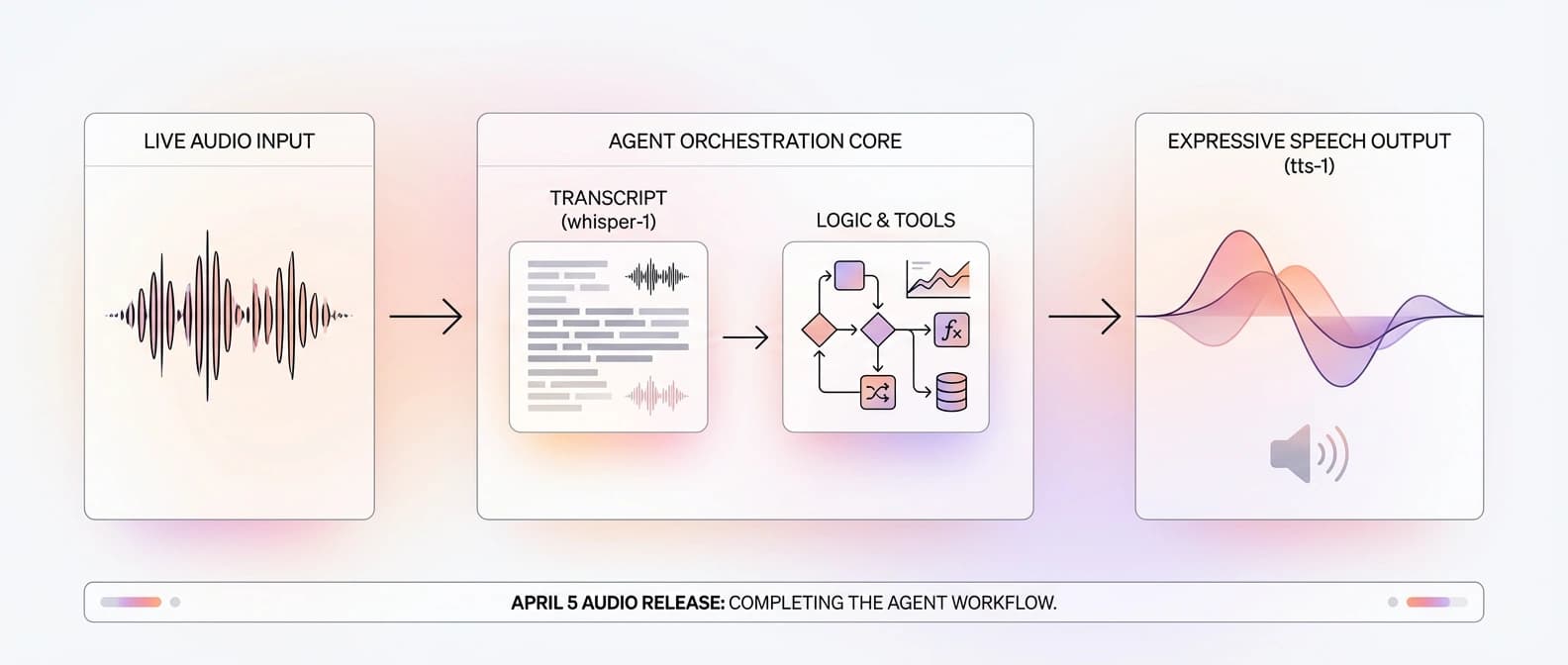
The launch post introduces gpt-4o-transcribe, gpt-4o-mini-transcribe, and gpt-4o-mini-tts, then says that adding OpenAI speech-to-text and text-to-speech models is the simplest way for teams with text-based systems to build a voice agent. The docs reinforce the same architecture: speech in, text reasoning in the middle, speech back out.
That matters because OpenAI already has the rest of the agent pitch in market. As we wrote in OpenAI's agent stack is a distribution play, not a demo, the company has been turning agents into a platform story, not a one-off showcase. This audio release fills in the missing layer. Turns out a voice agent is easier to sell when it can, in fact, do the voice part.
What actually shipped on April 5
The release post makes the headline points pretty clear. gpt-4o-transcribe and gpt-4o-mini-transcribe are the new speech-to-text models, and OpenAI says they improve word error rate, language recognition, and reliability versus the original Whisper line, especially in noisy settings, with accents, and across varying speech speeds. Those are OpenAI's claims, not neutral gospel, but they are directionally important because Whisper has been the default reference point for a lot of developers.
The new text-to-speech piece is gpt-4o-mini-tts, and this is where the stack gets more interesting. OpenAI is not just pitching it as another voice endpoint. It is pitching it as a steerable one: developers can tell it how to speak, not only what to say. That is a big deal for voice agents because the last thing most teams need is a support bot that sounds like it was trained by a haunted meditation app.
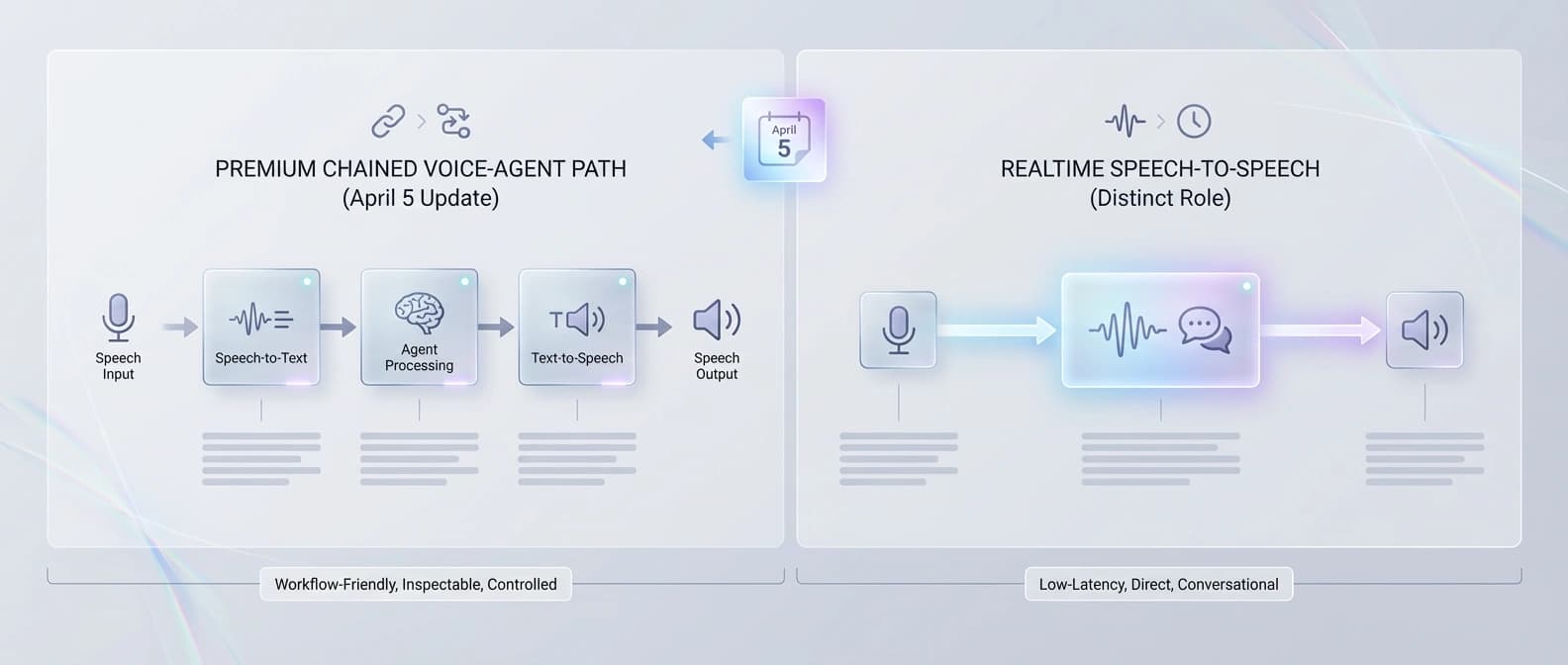
Then the docs widen the story. The audio overview page lays out the two main voice paths cleanly: use Realtime for low-latency speech-to-speech, or use the chained speech-to-text -> LLM -> text-to-speech pattern when you want more predictability and tighter control over the script. The Agents SDK voice quickstart turns that into an actual VoicePipeline abstraction. Suddenly this is not just a model drop. It is a documented assembly path.
There is also a quieter detail worth noting for people searching OpenAI speech-to-text diarize: the live speech-to-text guide now lists gpt-4o-transcribe-diarize on the transcription endpoint, with diarized_json output and speaker-segment support. That is useful if your "voice agent" workload looks more like calls, interviews, or meetings than pure realtime banter.
This is not Whisper with a fresh coat of paint
The easiest lazy take is that OpenAI simply refreshed Whisper branding and called it a day. I do not think that survives contact with the docs.
Whisper mostly gave developers transcription. This release gives them a more explicit voice workflow. The speech-to-text guide says the GPT-4o transcription models support prompts and logprobs, while the diarization path adds speaker labels on the HTTP transcription endpoint. The text-to-speech guide says gpt-4o-mini-tts can be instructed on tone, pacing, accent, emotional range, and style. The voice quickstart shows how that all snaps around an agent workflow instead of living as three unrelated API calls taped together at 2 a.m.
That is why this feels closer to stack completion than model refresh.
It also sharpens the contrast with other voice stories we have covered. Microsoft gives Foundry its own multimodal stack is a platform-ownership play. Gemini 3.1 Flash Live is Google's real-time agent rail is more about live interaction speed and session design. OpenAI's move sits in the middle: less theatrical than realtime demos, maybe, but much more practical for the huge class of teams that already have text agents and just want to let customers talk to them without building a small opera house around the integration.
No, this does not replace realtime speech-to-speech
This is the part where everyone needs to put down the "everything just changed" trumpet for a moment.
OpenAI's own audio guide still recommends the Realtime API for low-latency speech-to-speech experiences. The chained path is described as more predictable and easier to control, but it comes with added latency. So if you need rapid interruption handling, direct spoken turn-taking, or the most natural live conversation possible, this release is not a magic replacement for realtime.
The caveats get even more specific in the docs. gpt-4o-transcribe-diarize is currently available through /v1/audio/transcriptions and is not yet supported in the Realtime API. Custom voices also exist, but the text-to-speech guide says they are limited to eligible customers. So yes, you can get more expressive voice output now, but no, you should not promise the CEO a cloned brand voice five minutes before the demo.
And on the benchmark front, keep the attribution discipline tight. "State of the art" in the release belongs to OpenAI's framing. Fair to report, not fair to flatten into fact-without-owner.
So is the stack enough to build voice agents today?
For a lot of teams, yes.
If your product needs a reliable transcript, a controllable text-generation step, and spoken output on the other side, OpenAI now has a much cleaner answer than "start with Whisper, add your own glue, then pray over the latency chart." Support flows, meeting assistants, tutor experiences, intake bots, and structured call workflows all look more buildable after this release than they did a week ago.
That does not make OpenAI the only route. Voxtral TTS sells open control with a license catch points at one alternative direction for teams that care about openness and control. But if you are already inside OpenAI's ecosystem, this is the first moment where the company's agent story feels like it has a full conversational loop, not just the middle third of one.
That is why I would not file this under generic launch recap. The important part is not that OpenAI shipped fresh audio models. It is that the company finally connected speech recognition, agent orchestration, and speech output in a way normal developers can understand and wire up without building their own haunted telephone exchange.
That is a real platform upgrade. Even if the marketing copy still cannot resist a little chest-thumping, the underlying message is solid: OpenAI's agent stack now has a voice, and this time it comes with instructions.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Core release post for gpt-4o-transcribe, gpt-4o-mini-transcribe, gpt-4o-mini-tts, the voice-agent framing, and OpenAI's benchmark claims.
Confirms the launch page with lastmod 2026-04-05T00:43:06.987Z, which anchors the freshness claim.
Confirms the live transcription docs, supported GPT-4o transcription models, diarization path, prompt/logprob support, and the caveat that diarization is not yet in the Realtime API.
Confirms steerability for gpt-4o-mini-tts, built-in voice options, and the current gating for custom voices.
Supplies the key architecture split between low-latency realtime speech-to-speech and the chained speech-to-text -> LLM -> text-to-speech voice-agent pattern.
Confirms the VoicePipeline quickstart and the exact three-stage voice pipeline framing that makes the agent-stack argument concrete.

About the author
Idris Vale
Idris writes about the institutional machinery around AI, but the lens is broader than policy alone: procurement frameworks, public-sector buying rules, platform leverage, compliance burdens, workflow risk, and the market structure hiding beneath product or infrastructure headlines. The through-line is practical power, not abstract theater.
- 23
- Apr 10, 2026
- Brussels · London corridor
Archive signal
Reporting lens: Follow the buying process, not just the bill text.. Signature: Policy turns real when someone has to buy the system.
Article details
- Category
- AI Tools
- Last updated
- April 11, 2026
- Public sources
- 6 linked source notes
Byline
Tracks the institutions, incentives, and market structure that quietly decide which AI systems get deployed and why.



