GLM-5.1 coding agent and the 8-hour shift
Z.AI pitches GLM-5.1 as an 8-hour coding agent and documents manual routes into Claude Code, OpenClaw, and OpenRouter. Access is real. Proof is pending.

 ainewssilo.com
ainewssilo.comThe interesting GLM-5.1 claim is not that it writes code well. It is that Z.AI wants developers to judge it by whether it can survive a full shift.
Z.AI could have launched GLM-5.1 the normal way: one more benchmark chart, one more "frontier" adjective, one more request that everyone clap on command. Instead, it did something more revealing. It published docs that ask developers to judge the model by a full 8-hour coding shift, then showed how to route that bet into tools people already use.
That is why GLM-5.1 matters tonight.
The new GLM-5.1 overview does not just say the model is good at code. It says the model can work continuously and autonomously on a single task for up to 8 hours, and it pairs that with language about long-horizon execution, engineering optimization, and real-world development workflows. The companion Using GLM-5.1 in Coding Agent page then makes the pitch practical: here is how to swap GLM-5.1 into Claude Code, here is how to wire it into OpenClaw, here is how to treat familiar coding agents as the test bench.
That combination is the real story. The benchmark claims get the headlines. The workflow docs tell you what the company actually wants measured.
GLM-5.1's 8-hour coding agent pitch changes the question
Most model launches still ask to be judged like bright students in a short oral exam. GLM-5.1 is asking for something nastier: judge me by whether I stay useful after hours of tool calls, edits, retries, and small mistakes that would normally turn a demo into compost.
The overview page makes that framing unusually explicit. Z.AI says GLM-5.1 is aligned with Claude Opus 4.6 in general capability and coding performance, but stronger on long-horizon autonomous work. It also gives the model a 200K context window and 128K maximum output tokens, then pairs that with tool use, MCP support, structured output, and an agentic-coding positioning aimed straight at Claude Code and OpenClaw-style workflows.
A quick reality table helps separate the part that is new from the part that is still just a promise wearing expensive shoes:
| Claim | Where it appears | Why it matters | Caveat |
|---|---|---|---|
| Up to 8 hours of autonomous work on one task | z.ai GLM-5.1 overview | Moves the conversation from single-turn cleverness to time-on-task reliability | Vendor-published claim, not independently verified here |
| 58.4 on SWE-Bench Pro | z.ai GLM-5.1 overview | Gives the coding-agent story one concrete benchmark anchor | Earlier site coverage used 59.1 from a different GLM-5.1 source surface, so treat the decimal places with suspicion |
| Explicit routing into Claude Code and OpenClaw | z.ai coding-agent doc | Makes the claim testable in tools developers already tolerate | Setup is manual in key places, especially OpenClaw |
| Public OpenRouter listing | OpenRouter model page | Broadens access for teams already routing through provider layers | Listing does not validate autonomy, benchmark setup, or real-world durability |
That last row matters more than it first appears. An OpenRouter listing means GLM-5.1 is easier to sample from existing provider-switching habits. It does not mean OpenRouter has blessed the 8-hour story, replicated the benchmark numbers, or confirmed that the model remains sane at hour six when the test suite starts sulking.
Are Z.AI's long-horizon claims credible enough to care about?
Yes, with a raised eyebrow.
The reason I would not dismiss this launch is simple: Z.AI is making a more specific promise than usual. "Better coding" is mush. "Judge us by whether we can stay on one job for eight hours" is at least a real thing teams can try to break. The docs even describe the desired behavior in operational terms, like sustained execution, closed-loop optimization, and strategy stability over longer tasks. That is much more concrete than the usual benchmark victory lap.
It is also still a house claim.
Nothing in this source set independently proves that GLM-5.1 will hold up through a real eight-hour engineering task on your repo, your tools, and your charming collection of shell scripts written by three different past selves. The overview page includes eye-catching examples, including hundreds of iterations and large optimization gains, but those examples still live on the vendor's own surface. Useful signal, yes. Final verdict, no.
The SWE-Bench Pro wrinkle is another reason to stay careful. Our earlier coverage of GLM-5.1 hitting Hugging Face used 59.1 from a different GLM-5.1 release surface. This doc set says 58.4. That is not catastrophic. It is also not nothing. If a launch spans multiple surfaces with slightly different scoreboard language, readers should avoid acting like one decimal point settled the case forever. Benchmarks are already theatrical enough without us helping.
There is a smaller timing caveat too. The z.ai pages do appear freshly updated today based on HTML-level timestamp clues and asset markers, which supports the "why now" angle. But those clues are not clean public publish labels. So the right wording is "appears freshly updated," not "formally published at exactly this minute with a trumpet fanfare."
In other words, the claims are credible enough to test. They are not credible enough to inherit.
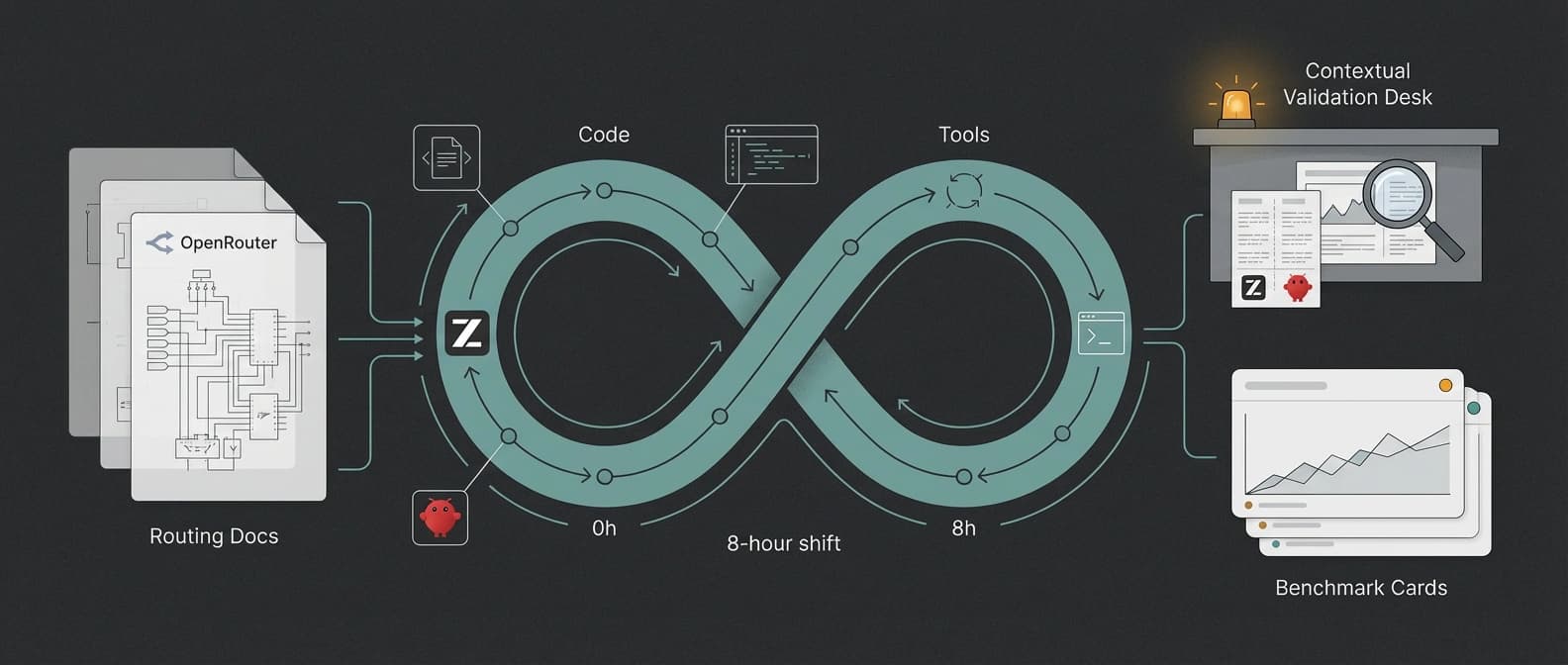
How to use GLM-5.1 in Claude Code, OpenClaw, and OpenRouter
This is where the launch gets more interesting and less mystical.
The coding-agent doc tells Claude Code users to edit ~/.claude/settings.json and remap the default Anthropic slots so Sonnet and Opus point to glm-5.1. That is manual, but it is familiar manual. Many developers will accept a settings-file edit if it buys them a cheaper or more experimental engine behind a tool they already like.
The OpenClaw route is rougher. For users who already set up the Z.AI provider, the doc says to edit ~/.openclaw/openclaw.json, add a new glm-5.1 model entry under models.providers.zai.models, switch agents.defaults.model.primary to zai/glm-5.1, add zai/glm-5.1 under agents.defaults.models, and restart the gateway. That is not first-class native selection. That is a wrench-and-JSON workflow. Still, it is a real route, and it builds directly on the groundwork we covered in GLM-5.1's earlier Claude Code and OpenClaw push and in the separate OpenClaw OpenAI-compatible gateway story.
I actually like that the doc is this explicit. Vague compatibility language is how teams lose an afternoon and then write angry forum posts in all lowercase.
OpenRouter adds a third lane. The public GLM 5.1 listing means teams that already use provider routing can reach the model without rebuilding their whole stack around z.ai's own first-party surfaces. That lowers the experiment cost. It does not remove the evidence problem.
Here is the practical routing picture tonight:
| Route | What you get | Setup burden | The fine print |
|---|---|---|---|
| Claude Code | Familiar shell, fast test of the model inside an established workflow | Moderate, edit settings.json and relaunch | Still a manual remap, not a native one-click model choice |
| OpenClaw | Strong fit for operators already comfortable with provider routing and gateway control | Higher, edit openclaw.json and restart the gateway | Manual config path, not turnkey native support |
| OpenRouter | Easier access inside existing provider-switching habits | Lower if the team already uses OpenRouter | Listing proves availability, not performance or long-horizon reliability |
That combination is why this is more than an ordinary docs update. Z.AI is not only selling intelligence. It is selling low-friction trialability inside somebody else's workflow.
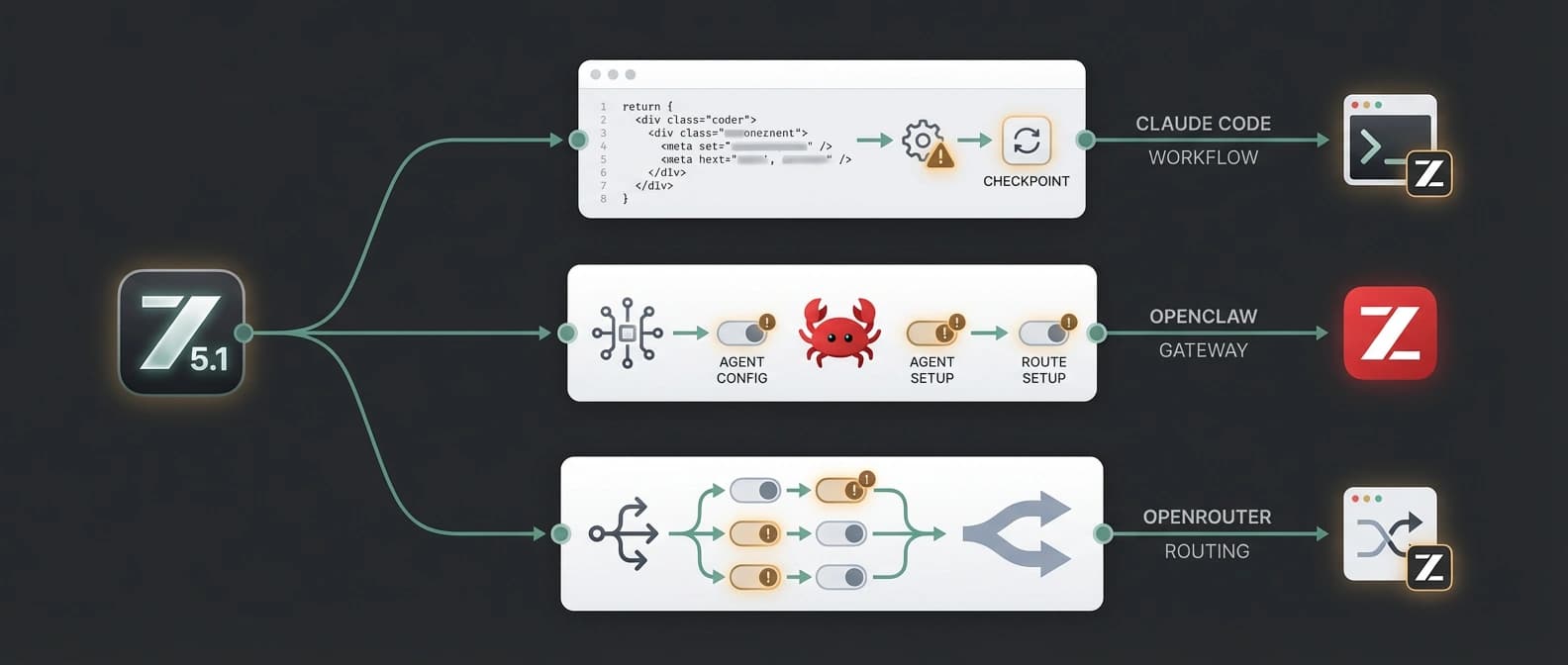
GLM-5.1 vs other coding agent options tonight
GLM-5.1 is not entering an empty room. It is entering a room full of models and tools all claiming they can babysit a repo without setting the curtains on fire.
A simple comparison helps:
| Option | Strongest pitch tonight | Why a team might pick it | Main limitation |
|---|---|---|---|
| GLM-5.1 via z.ai docs | The clearest long-horizon claim, with explicit Claude Code and OpenClaw routing docs | You want to test the 8-hour persistence bet inside familiar tools | Core autonomy claim is still vendor-published |
| Qwen3.6-Plus | Repo-scale coding, multimodal context, and long context framing | You care about broad repo work more than the "full shift" story | Also heavily benchmark-led, and still a hosted path |
| GitHub Copilot CLI BYOK with local models | Familiar CLI and more freedom over model choice | You want workflow continuity and provider flexibility, especially with your own model stack | Not the same as having one vendor openly staking its reputation on 8-hour autonomy |
| GLM-5.1 open weights on Hugging Face | Inspectable weights and more independent deployment scrutiny | You want to test the model outside pure vendor hosting | Infrastructure load is heavy enough to ruin a casual evening |
That is why I would read GLM-5.1 less as "the winner" and more as "the vendor making the sharpest duration claim right now." Duration is the point. Lots of models can look smart for fifteen minutes. The useful question is which one still looks organized after a long stretch of edits, failures, and tool chatter.
What developers should test before trusting an 8-hour coding agent
If you are tempted to try GLM-5.1, do not start by reproducing the prettiest benchmark. Start with an ugly real task.
Give it a live repository. Ask for a bounded but annoying job: fix a failing integration, update tests, touch one UI path, and keep notes coherent while tools return messy output. Interrupt it. Force a retry. Change the brief halfway through. Make it earn the long-horizon branding.
The boring tests matter most:
| Test | What success looks like | Why it matters |
|---|---|---|
| Long session coherence | The agent still knows the goal after hours, not minutes | This is the whole sales pitch |
| Failure recovery | Tool errors lead to legible retries instead of hallucinated confidence | Real coding work breaks rhythm constantly |
| Repo discipline | Changes stay scoped, explained, and test-backed | Long tasks are where sloppy drift gets expensive |
| Human takeover | A developer can inspect and resume without decoding nonsense | Eight-hour autonomy is pointless if handoff is unreadable |
If GLM-5.1 stays calm through that kind of test, the launch starts to feel serious. If it falls apart at minute 23, then the market has learned something useful without donating a whole shift to marketing copy.
That is the bottom line tonight. Z.AI has not merely said GLM-5.1 is strong at coding. It has said the model should be judged by how long it can keep working, and it has published the docs that let developers run that experiment inside Claude Code, OpenClaw, and OpenRouter-adjacent workflows.
That is a more interesting claim than another benchmark chart. It is also a more dangerous claim, because this one can be tested in the open. Good. Coding-agent launches need less applause and more endurance checks.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Main source for the long-horizon positioning, the 8-hour autonomous-task claim, the 58.4 SWE-Bench Pro score, and the Claude Opus 4.6 comparison language.
Core evidence for the manual Claude Code and OpenClaw configuration paths, plus the fact that z.ai is explicitly documenting familiar-tool routing.
Confirms the public OpenRouter listing, which expands availability but does not independently validate z.ai's autonomy or benchmark claims.

About the author
Idris Vale
Idris writes about the institutional machinery around AI, but the lens is broader than policy alone: procurement frameworks, public-sector buying rules, platform leverage, compliance burdens, workflow risk, and the market structure hiding beneath product or infrastructure headlines. The through-line is practical power, not abstract theater.
- 23
- Apr 10, 2026
- Brussels · London corridor
Archive signal
Reporting lens: Follow the buying process, not just the bill text.. Signature: Policy turns real when someone has to buy the system.
Article details
- Category
- AI Tools
- Last updated
- April 11, 2026
- Public sources
- 3 linked source notes
Byline
Tracks the institutions, incentives, and market structure that quietly decide which AI systems get deployed and why.



