GitHub Squad makes repo-native multi-agent work real
GitHub Squad turns multi-agent coding into a concrete repo-native pattern, with shared decision files, separate reviewer agents, and team memory that lives in git.

 ainewssilo.com
ainewssilo.comSquad's real idea is not more agents. It is putting team memory, routing, and review rules into files you can inspect, clone, and commit.
Multi-agent coding has had a marketing problem for a while. The pitch is always a tidy little AI company inside your laptop. The reality is usually one model doing costume changes and hoping nobody notices the fake mustache.
That is why GitHub's March 19 write-up on Squad, updated March 20, caught my attention. It is not interesting because it promises an AI team. Everybody promises an AI team now. It is interesting because it shows a concrete repo-native orchestration pattern built around files you can inspect, commit, diff, and hand to the next person who clones the repo.
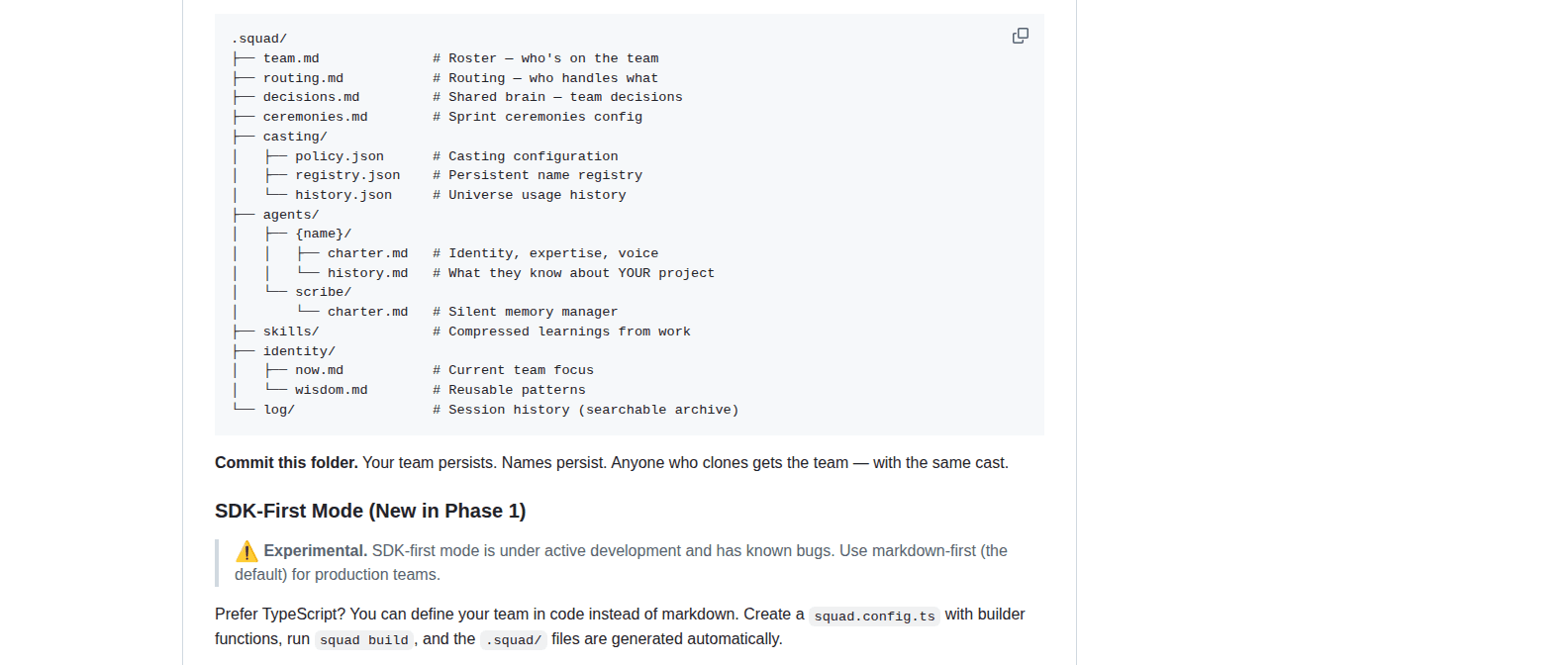
Squad is an open-source project built on GitHub Copilot. The install story is almost suspiciously short: install the CLI, run squad init, and the repo gets a lead, frontend developer, backend developer, and tester. Fine. Cute. The part that matters comes after that. Squad stores the team's memory inside a .squad/ folder with team.md, routing.md, decisions.md, agent charters, agent histories, and searchable logs. In other words, the team does not live in a spooky hidden service somewhere. It lives in git.
I like that because it turns the usual multi-agent pitch into something far less mystical and much more useful.
GitHub Squad gives multi-agent orchestration a home address
The GitHub blog post describes a thin coordinator that routes work, loads repository context, and spawns specialists with task-specific instructions. That part is familiar enough. The more interesting design choice is where the system keeps state.
Squad's README says anyone who clones the repo gets the team and its accumulated knowledge. That is a bigger deal than the install command. The .squad/ directory includes shared routing rules, project decisions, current focus notes, reusable team wisdom, and per-agent history files. The repo stops being just code storage and starts acting like a small, slightly eccentric office that keeps excellent minutes.
That is also why this story fits neatly with our earlier piece on AI coding's new bottleneck: agent orchestration. The hard part is no longer getting one model to spit out a patch. The hard part is deciding who works on what, what gets remembered, what happens after failure, and how the next session avoids starting from scratch like a goldfish with a terminal.
Squad makes a strong bet on the answer: keep the coordination artifacts in the repository itself, where humans can see them and version control can do its boring, glorious job.
The shared decision file is the real GitHub Squad trick
GitHub's post calls this the "drop-box" pattern for shared memory. Instead of pretending a live swarm of agents will stay perfectly synchronized, Squad appends structured decisions to decisions.md. A library choice, a naming convention, a database call, a policy decision, it all goes into the shared file.
That sounds plain. Good. Plain is doing a lot of work here.
A versioned decision file gives the team an audit trail, persistence across restarts, and something humans can read without needing to reverse-engineer a model's vibes. If the team chose a framework last Tuesday, you can inspect the file. If the call looks dumb in hindsight, you can blame a markdown diff instead of holding a séance for the context window.
I keep seeing the same pattern across agent tooling. The useful innovations are often the boring interface moves that make a system legible. We saw that in OpenClaw's OpenAI-compatible gateway, where the clever bit was not more AI theater but a cleaner contract with the rest of the stack. Squad does something similar for team memory. It makes the memory visible.
That visibility matters because a lot of multi-agent hype still sounds like "trust us, the agents talked." I would rather read the notes.
Separate reviewer agents make the workflow less self-flattering
The most grown-up part of GitHub's explanation is the reviewer protocol. In the blog post's example loop, the tester runs a suite against the backend specialist's work. If the tests fail, the reviewer can reject the code, and the orchestration layer can prevent the original author from fixing its own rejected draft. A different agent has to step in.

That is not a tiny implementation detail. That is the whole difference between a review loop and a self-esteem loop.
A model reviewing its own failed patch has the same energy as a teenager being asked to investigate who ate the cake. You may get an answer. You should still want a second witness.
Squad's insistence on separate contexts for separate roles is what makes the pattern feel concrete instead of theatrical. The coordinator routes. Specialists work. Reviewers review. Shared files hold the team's memory. Humans still approve and merge the pull request that survives the loop. GitHub's post is explicit about that part: this is collaborative orchestration, not autopilot.
That separation also makes Squad feel different from some of the broader market noise around Claude Code's plugin aftermarket and Claude Code's browser race. Those stories show the coding-agent stack expanding outward into wrappers, control layers, and browser seats. Squad is working on a quieter question inside the repo: how do agents remember, disagree, and hand work off without turning the project into agent soup?
The alpha warning is part of the GitHub Squad story too
None of this means Squad is finished. The README labels it alpha software and says APIs and CLI commands may change. It also flags SDK-first mode as experimental and buggy. That caveat should stay in big friendly letters.
Still, I do not think the alpha label weakens the main point. If anything, it sharpens it. Squad matters less as a verdict on one specific tool and more as proof that persistent AI team state inside the repo is a real pattern now, not just a vague aspiration in conference slides.
That is what I am taking away from GitHub's write-up. The repo-native idea is concrete. Shared decision files are concrete. Reviewer separation is concrete. Cloning a repo and inheriting the team's memory is concrete. The repo itself becomes the substrate for orchestration.
That is a lot less magical than the usual multi-agent pitch. It is also a lot closer to how real engineering teams actually work: notes, handoffs, history, and somebody else checking your work before it touches main.
Not glamorous. Better.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Primary source for GitHub's March 19 and March 20 framing of Squad, including the repository-native orchestration patterns, reviewer separation, and shared decision-file design.
Primary source for the alpha warning, the .squad folder structure, command surface, and the repo-level persistence model that lets cloned projects inherit team state.

About the author
Lena Ortiz
Lena tracks the economics and mechanics behind AI systems, from serving architecture and open-weight deployment to developer tooling, platform shifts, product decisions, and the operational tradeoffs that shape what teams actually run. Her reporting is aimed at builders and operators deciding what to trust, adopt, and maintain.
- 24
- Apr 10, 2026
- Berlin
Archive signal
Reporting lens: Operating leverage beats ideological posturing.. Signature: If the cost curve moves, the product strategy moves with it.
Article details
- Category
- Open Source AI
- Last updated
- April 11, 2026
- Public sources
- 2 linked source notes
Byline
Covers the economics, tooling, and operating realities that shape how AI gets built, shipped, and run.



