Gemma 4 models explained: E2B, E4B, 26B A4B, and 31B
Gemma 4 is not one model. Google's E2B, E4B, 26B A4B, and 31B force real choices about memory, latency, audio, context, and reasoning quality.

 ainewssilo.com
ainewssilo.comGemma 4 matters because it is not one open model. It is four different tradeoff decisions wearing one launch jacket.
Gemma 4 is being marketed as one launch, but that is only true in the same way a restaurant menu is "one meal." Technically, yes. Practically, no.
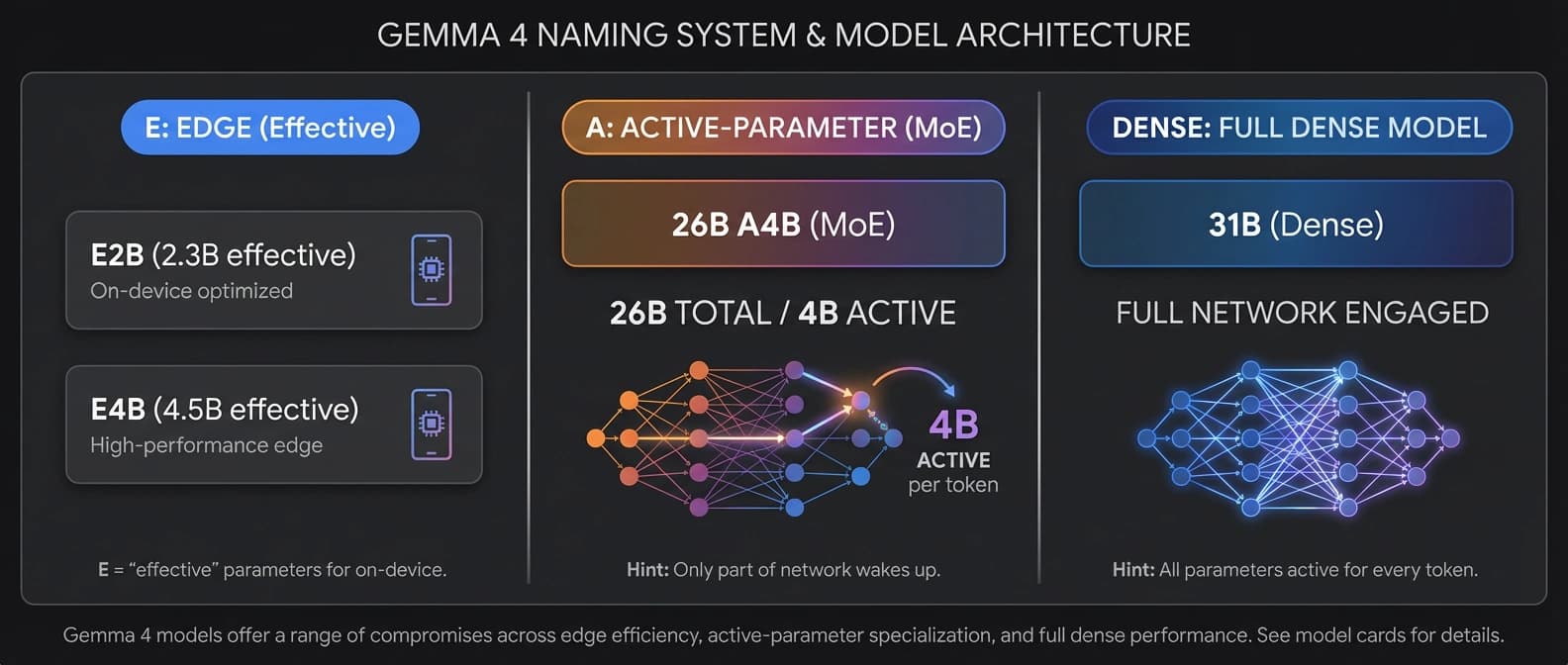
Google shipped four variants under the same family name: E2B, E4B, 26B A4B, and 31B. On paper that looks tidy. On real hardware it is not. Two are edge-first multimodal models with audio support. One is a mixture-of-experts model whose runtime bill is much closer to a 4B model than its 26B badge suggests. One is a dense 31B model that is slower and heavier but still the cleanest answer when you want the best quality in the family.
That, to me, is the real Gemma 4 story.
Our earlier piece on Gemma 4 as Google's Apache 2.0 local agent stack was about deployment. This one is about the question that arrives five minutes later and matters more: which of these four things are you actually supposed to run?
That is where the launch gets messy in a useful way. Audio exists only on E2B and E4B. The edge models stop at 128K context; 26B A4B and 31B reach 256K. The MoE model's speed story comes from its 3.8B active parameters, while its memory story still has to account for a much larger total model. And the 31B dense model remains the benchmark leader inside the family, which is nice until your laptop starts sounding union-adjacent.
So the useful way to read Gemma 4 is not as a single benchmark hero. It is as a decision tree.
Gemma 4 is a model family, not a single answer
Google's own launch post and model card make the split fairly explicit once you stop looking at the family portrait and start reading the labels. The lineup breaks into three buckets.
First, there are the edge models: E2B and E4B. These are the small, efficient, audio-capable members of the family. They support text, image, and audio input; they ship with 128K context windows; and Google positions them for phones, laptops, Raspberry Pi-class devices, and other edge hardware. These are the models that show up in the on-device story around AI Edge Gallery, LiteRT-LM, and Android AICore.
Second, there is the latency play: 26B A4B. This is the one that looks confusing until you read the fine print. It is a 25.2B-parameter mixture-of-experts model, but only 3.8B parameters are active during inference. Google and Hugging Face both frame that as the point. You are meant to get much closer to workstation-class quality without paying dense-31B compute on every token.
Third, there is the quality-first dense model: 31B. This is the straightforward one. No MoE routing trick. No effective-parameter naming convention. Just 30.7B dense parameters, a 256K context window, text-and-image multimodality, and the best benchmark scores in the family.
A quick decoder table helps before the naming scheme starts bullying people:
| Model | What the label really means | Context window | Native modalities | Best first guess |
|---|---|---|---|---|
| E2B | Edge model with 2.3B effective parameters and 5.1B with embeddings | 128K | Text, image, audio | Phones, Raspberry Pi, voice-heavy edge experiments |
| E4B | Edge model with 4.5B effective parameters and 8B with embeddings | 128K | Text, image, audio | Small laptops, local assistants, stronger multimodal edge use |
| 26B A4B | MoE model with 25.2B total and 3.8B active parameters | 256K | Text, image | Fast local coding, OCR, assistants on decent consumer GPUs |
| 31B | Dense model with 30.7B parameters | 256K | Text, image | Highest quality, best evals, strongest fine-tuning base |
That is already enough to avoid one common mistake: assuming the biggest number in the name tells you the whole story. It does not. In Gemma 4, letters matter as much as digits.
What E, A, and dense actually mean
The most important Gemma 4 terms are also the easiest to misread.
The E in E2B and E4B stands for effective parameters, not total parameters. According to the model card and the Hugging Face launch write-up, those edge models use Per-Layer Embeddings, or PLE, to keep runtime compute lower while still injecting token-specific information into each decoder layer. That is why Google can call E2B a 2.3B effective model even though the full count rises to 5.1B with embeddings, and E4B a 4.5B effective model even though the total with embeddings reaches 8B.
This is a useful distinction, but it needs translation. Effective parameters are trying to tell you what the model feels like to run, not what every stored weight would total in a giant spreadsheet.
The A in 26B A4B stands for active parameters. The model is a mixture-of-experts system with 128 total experts plus one shared expert, and the model card says 8 experts are active at inference time. So you are not pushing all 25.2B parameters through every token. You are waking up a routed subset, which is why the model behaves more like a 4B-class compute load than a 26B dense monolith.
The nuance people flatten away is simple: active compute and stored memory are not the same bill. A MoE model can be efficient per token while still needing meaningful memory to hold the underlying weights. If you have read our breakdown of open-weight inference economics, this is the same lesson in a new outfit.
Then there is dense. Dense is less flashy and more literal. Every layer works every time. You pay for it, but you also get simpler behavior and cleaner fine-tuning expectations. That is why Google presents 31B as both the raw-quality option and the stronger base for adaptation.
The naming system sounds fiddly because it is fiddly. The distinctions are still real.
Gemma 4 E2B vs E4B: same edge idea, different patience
E2B and E4B are the part of Gemma 4 that makes the most sense once you stop expecting them to win every benchmark table. They are not trying to be miniature 31Bs. They are trying to be useful on actual edge hardware.
Both models support text, image, and audio input. Both top out at 128K context. Both use PLE. Both have relatively small vision encoders at around 150M parameters and audio encoders at around 300M. Both can process video, but the model card is careful here: video is handled as sequences of frames, and the documented maximum is 60 seconds assuming one frame per second. Audio support also has a stated limit: 30 seconds. That matters because a lot of launch language makes multimodality sound like an abstract superpower. In practice, these are bounded interfaces with concrete caps.
The more interesting difference between E2B and E4B is not philosophy. It is headroom.
E2B is the model you reach for when the device is the story. Google, Arm, and NVIDIA all lean hard into this edge narrative. Google's edge post says LiteRT-LM can run Gemma 4 E2B on Raspberry Pi 5 at 133 tokens per second prefill and 7.6 tokens per second decode, and Arm's launch note says early engineering tests on SME2-enabled Arm CPUs showed an average 5.5x prefill speedup and up to 1.6x faster decode on Gemma 4 E2B. Those are not universal guarantees. They are platform-specific results, some of them from partners, and they should be read that way. Still, the pattern is obvious: E2B is the model Google and its ecosystem want living on phones, tiny edge boards, and offline assistants.
That is also why E2B gets more interesting when the task is speech, local transcription, or simple on-device assistance rather than hard reasoning. Only E2B and E4B support native audio. So if your application needs speech recognition, speech translation, or voice-first interaction, the larger Gemma 4 models are not even in the running. The decision tree narrows instantly.
E4B is the more comfortable edge choice when you have slightly more room and do not want every hard prompt to turn into a test of personal character. It keeps the same modality mix and the same 128K context, but it gives you more reasoning headroom, stronger multimodal scores, and noticeably better performance across the core benchmark table. On the model card, E4B posts 69.4% on MMLU Pro versus 60.0% for E2B. On MMMU Pro, the gap is 52.6% versus 44.2%. On LiveCodeBench v6, it is 52.0% versus 44.0%. For audio benchmarks, E4B also edges ahead, posting 35.54 on CoVoST and 0.08 on FLEURS versus E2B's 33.47 and 0.09.
None of those numbers turn E4B into a workstation replacement. They do tell you something more useful: if you want a Gemma 4 model that can still live on local hardware while handling OCR, image grounding, UI understanding, or a voice-enabled assistant with less strain, E4B is usually the more forgiving pick.
I would put it this way. E2B is the one you choose when you are trying to make a device class possible. E4B is the one you choose when you are trying to make a product feel decent.
That distinction matters because the edge story around Gemma 4 can tempt people into overgeneralizing. Yes, the small models are surprisingly capable. Yes, Google's AICore Developer Preview and AI Edge tooling make them easier to test on supported devices. No, that does not mean they are the right answer for every local workload. They are edge models first. Benchmark contestants second.
Gemma 4 26B A4B vs 31B: speed against certainty
This is the real fork in the road for most developers who are not building for phones.
If you have enough memory for a serious local model and you care about coding, OCR, long documents, or a local assistant that feels more adult than toy-like, the choice is usually not E4B versus E2B. It is 26B A4B versus 31B.
Google's own framing is unusually candid here. In the main launch post, the company basically assigns each model a role. 26B A4B is the latency play. 31B is the quality and fine-tuning play. That is one of the cleaner model-family disclosures we have had in a while, and I wish more labs would be this plain.
Start with 26B A4B. The magic trick is active parameters. The model card says it has 25.2B total parameters but only 3.8B active parameters during inference. Hugging Face makes the same point and adds the practical translation: it runs almost as fast as a 4B model in some respects while staying much closer to dense-31B quality than the nameplate alone would imply.
That shows up in the benchmark table. On MMLU Pro, 26B A4B scores 82.6% versus 85.2% for 31B. On AIME 2026 without tools, it posts 88.3% versus 89.2%. On LiveCodeBench v6, it lands at 77.1% versus 80.0%. On MMMU Pro, it reaches 73.8% versus 76.9%. That is not a blowout. That is a respectable tax for a model designed to move faster.
And speed does matter. It matters for local coding loops. It matters for assistants that need to stay interactive. It matters for computer-use or OCR pipelines where waiting three extra beats on every call makes the whole system feel theatrical in the bad way.
Both 26B A4B and 31B offer 256K context windows, which makes them the obvious choice for big repositories, long legal documents, giant PDF bundles, or note archives that would make lightweight models quietly panic. Pair that with the MoE model's active-parameter efficiency and 26B A4B starts to look like the practical sweet spot for builders who want a lot of context without going full workstation martyr.
But 31B still wins when the question is simply, "Which Gemma 4 gives me the best answers?" It leads the family's published benchmarks across reasoning, coding, multilingual evaluation, multimodal reasoning, and document tasks. The model card gives 31B the top in-family numbers on GPQA Diamond, Tau2, BigBench Extra Hard, MMMLU, OmniDocBench, and MATH-Vision. Google also places it above 26B A4B on Arena AI's open text leaderboard.
Dense also tends to be the less confusing foundation when you want to adapt a model rather than just run it. Google says the 31B model provides a strong basis for fine-tuning, and that tracks with how dense checkpoints usually behave in practice.
So which one should you choose?
If you care about speed per token, interactive local use, and good-enough-to-very-good quality on a consumer GPU, 26B A4B is probably the sharpest Gemma 4 option.
If you care about max quality, best benchmark headroom, cleaner fine-tuning expectations, or simply not second-guessing the family leader, 31B remains the adult answer.
The simplest way I can put it is this: 26B A4B is the clever choice. 31B is the calm choice.
Gemma 4 benchmarks: what the launch slides hide
Gemma 4's benchmark story is strong. It is also easy to flatten into nonsense.
Google, DeepMind, and Hugging Face all have every reason to emphasize the headline wins: 31B ranks near the top of the open-model pile, 26B A4B comes surprisingly close, and even the small models look much better than their size suggests. None of that is fake. The trouble starts when those results get read as if they describe one universal ordering for every workload.
They do not.
The benchmark table itself mixes text reasoning, coding, multimodal understanding, audio, and long-context retrieval. Some results are explicitly no-tools. Some rely on search. Arena AI is a text leaderboard with preference-style dynamics, not a settled scientific law. Tau2 is about agentic tool use. OmniDocBench is document-heavy. CoVoST and FLEURS only apply to the small audio-capable models. HLE appears only for the larger models.
That is why I keep coming back to our earlier piece on benchmark trust recession. The problem is not that the benchmarks are worthless. The problem is that launch framing always wants to convert a many-axis tool into one clean trophy photo.
Gemma 4 is especially vulnerable to that simplification because the family name invites aggregation. "Gemma 4" sounds like one thing. The data says otherwise.
A few practical caveats matter:
- Audio is not family-wide. If you care about speech, your real benchmark universe narrows to E2B and E4B immediately.
- Video is frame-based. The model card describes video handling as processing sequences of frames, not some magical end-to-end video-native stack.
- Long context is uneven. E2B and E4B top out at 128K, while 26B A4B and 31B reach 256K.
- Partner hardware claims are partner claims. Arm's SME2 numbers and NVIDIA's local deployment framing are useful signals, not universal field results.
- Training cutoff still matters. The model card says the pretraining data cuts off in January 2025. A 256K window does not turn that into live knowledge. It just means you can stuff more current material into the prompt.
That last point matters more than people admit. Long context has a habit of sounding like intelligence when sometimes it is just a larger backpack. A useful backpack, yes. Still a backpack.
There is also a smaller but very practical benchmark caveat around multimodality. The family supports variable image aspect ratios and configurable image token budgets. Ollama's deployment notes list budgets from 70 up to 1120 visual tokens. That means results on OCR, chart reading, or document parsing can shift depending on how much visual detail you preserve. If you squeeze the image budget for speed, you may get a less flattering real-world outcome than the benchmark headline suggests. If you raise it, you pay more compute. Again: one family, several tradeoffs.
Gemma 4 hardware requirements: the practical envelopes
Google's official materials describe fit classes more than hard minimum requirements. The company says the E2B and E4B models are designed for mobile and IoT hardware, while 26B A4B and 31B can fit in unquantized bfloat16 form on a single 80GB H100 and run locally on consumer GPUs once quantized. That tells you where the family is meant to live, but not exactly what your own machine will tolerate.
For practical local deployment numbers, community sources are more blunt. Unsloth's local guide is the most useful one in the source pack, and it should be treated as community guidance rather than official Google gospel. Its rough memory estimates for quantized inference look like this:
| Gemma 4 variant | 4-bit memory guidance | 8-bit guidance | Higher-precision guidance |
|---|---|---|---|
| E2B | about 4-5 GB | about 5-8 GB | about 10-15 GB |
| E4B | about 5.5-6 GB | about 9-12 GB | about 16 GB |
| 26B A4B | about 16-18 GB | about 28-30 GB | about 52 GB |
| 31B | about 17-20 GB | about 34-38 GB | about 62 GB |
Those numbers are a decent reality check. They also underline why the model family exists in four pieces.
E2B and E4B are what make phones, thin laptops, Raspberry Pi 5 boards, and lightweight offline assistants feel plausible. Google's edge tooling story reinforces that. The AICore Developer Preview lets supported Android devices opt into preview on-device models, though Google warns those preview builds may be slower, less accurate, and occasionally less stable than production versions. LiteRT-LM extends the same general edge story across Linux, macOS, Raspberry Pi, and Python pipelines. If your deployment target is constrained hardware or offline mobile UX, that ecosystem gravity matters as much as raw benchmark rank.
26B A4B is where consumer GPUs and beefier unified-memory laptops start to feel comfortable, especially with 4-bit quantization. This is the model I would look at first for local coding assistants, OCR-heavy workflows, and long-context personal knowledge tools if the machine has enough memory but not enough patience for a full dense 31B all day.
31B is the model that asks for a little more dignity from the hardware. It is not absurdly large by frontier standards, but it is still the family member most likely to push you toward a real workstation, a high-memory Mac, or a substantial GPU setup if you want smooth local inference. The reward is that you stop compromising first.
Task shape matters more than raw size. For OCR and document parsing, both 26B A4B and 31B look materially better than the edge models, with 31B holding the best OmniDocBench result in the family. If your workload is invoices, PDFs, tables, and chart reading, the bigger models are the safer start, and our look at Granite 4 Vision's document AI angle is a useful reminder that accuracy here often earns the extra memory.
For local assistants with speech, the decision swings back to E2B or E4B because only those models support audio. For fine-tuning, Google's own launch framing nudges you toward 31B. For fast local coding and tool use, 26B A4B may be the better compromise. And for sovereign or institution-controlled local deployments, the broader argument still lines up with our earlier look at Microsoft's local sovereign AI stack: the model is only part of the decision.
Which Gemma 4 model should you pick?
Here is the blunt version.
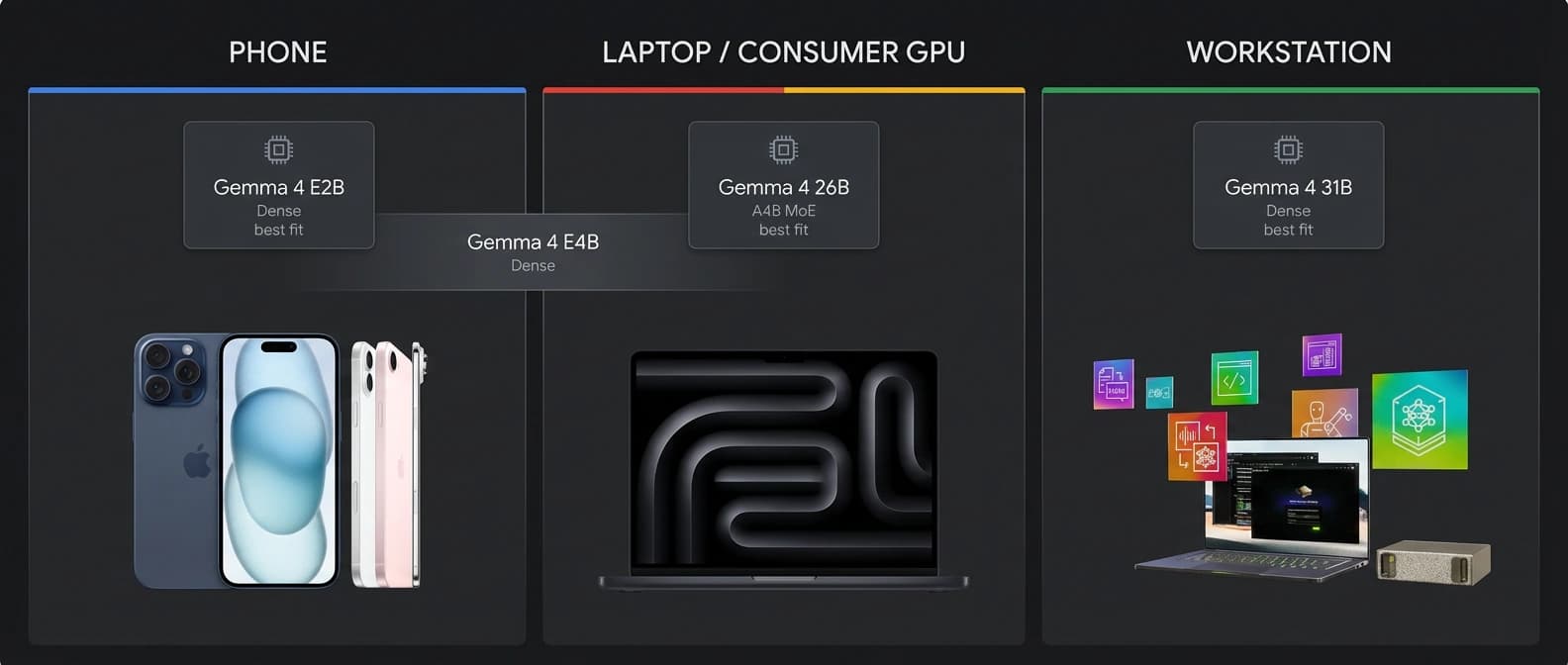
If you are building for a phone, embedded board, or offline edge assistant, start with E2B. It is the clearest fit for minimal memory budgets, voice-related tasks, and cases where getting anything competent to run locally is already a win.
If you want a more capable local multimodal assistant on a laptop or modest machine, especially one that needs audio input, start with E4B. It buys you meaningful quality without abandoning the whole edge premise.
If your workload is local coding, OCR, long-context research, or a desktop assistant on a serious consumer GPU, start with 26B A4B. It is the Gemma 4 model most likely to make you feel clever for choosing it.
If you want the best Gemma 4 quality available, or you are choosing a base for evaluation-heavy work and future tuning, start with 31B. It is not mysterious. That is part of the appeal.
A more concrete matrix:
| Use case | Best first pick | Why | Main warning |
|---|---|---|---|
| Phone app or edge device | E2B | Lowest effective footprint, audio support, strongest device-first story | Hard prompts hit the ceiling sooner |
| Laptop voice assistant | E4B | Audio support plus better reasoning and vision than E2B | Still far behind 26B/31B on tougher tasks |
| Local coding assistant | 26B A4B | Best speed-quality tradeoff in the family | No audio, and memory is still real despite 4B-active framing |
| OCR or document-heavy workflow | 31B or 26B A4B | Best multimodal and doc-task performance | Requires substantially more hardware than the edge models |
| Fine-tuning base | 31B | Dense, strongest quality, explicitly pitched that way by Google | Heavier and slower |
| Speech transcription or speech translation | E4B or E2B | Only audio-capable Gemma 4 models | Give up 256K context and top-end reasoning |
| General local assistant on a good workstation | 26B A4B first, 31B if quality wins | 26B feels nimble, 31B feels safer | Pick based on whether latency or answer quality hurts more |
That matrix is why I do not think Gemma 4 should be discussed as a single launch hero. Google did something smarter than that. It shipped one open family that covers four distinct deployment bets:
- a tiny edge entry point
- a roomier edge model
- a clever MoE workstation compromise
- a dense quality leader
Once you read the release that way, the family gets easier to understand and more interesting to use.
The benchmark story becomes less magical. The hardware story becomes more concrete. And the model-picking question stops sounding like a minor implementation detail.
That is the real value here. Gemma 4 does not just give developers an open model to admire. It forces them to decide what they actually care about: memory, latency, audio, context, or peak reasoning. That is a better problem than most launches leave behind.
And honestly, I prefer it. A benchmark chart can impress you for a day. A well-split model family can save you a month of buying the wrong hardware.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Primary launch framing for the four-model family, Apache 2.0 licensing, context windows, modality support, and Google's own positioning of E2B/E4B as edge bets, 26B A4B as the latency play, and 31B as the quality and fine-tuning foundation.
Most important technical source for effective versus active parameters, modality limits, context windows, architecture details, benchmark tables, video-as-frames behavior, audio limits, and the January 2025 training-data cutoff.
Useful for the official benchmark framing, Arena AI positioning, and the broad capability summary across the family.
Key source for the practical edge story around E2B and E4B, AI Edge Gallery Agent Skills, LiteRT-LM CLI, Raspberry Pi 5 throughput claims, and Android AICore availability.
Best plain-language external explanation of the architecture mix, especially Per-Layer Embeddings, shared KV cache, and the distinction between E-model efficiency and MoE routing.
Model-table source for modality support, context windows, benchmark values, and the dense-model explanation that helps compare 31B to the rest of the family.
Model-table source for the MoE explanation, 3.8B active-parameter behavior, expert count, and the 26B A4B performance framing.
Useful for practical local-run guidance, modality ordering advice, variable image token budgets, and a deployer-facing summary of the family.
Community hardware-envelope estimates for quantized local inference. Use carefully as practical guidance, not as official Google minimum requirements.
Partner source for SME2 performance claims on Gemma 4 E2B and the Android-scale case for on-device deployment. Treat performance numbers as partner engineering results.
Partner source for local GPU and Jetson framing across RTX PCs, workstations, DGX Spark, and Jetson Orin Nano. Treat performance framing as partner positioning.
Confirms the AICore Developer Preview mechanics, supported-device caveats, and the fact that preview models can be slower or less stable than production releases.

About the author
Idris Vale
Idris writes about the institutional machinery around AI, but the lens is broader than policy alone: procurement frameworks, public-sector buying rules, platform leverage, compliance burdens, workflow risk, and the market structure hiding beneath product or infrastructure headlines. The through-line is practical power, not abstract theater.
- 23
- Apr 10, 2026
- Brussels · London corridor
Archive signal
Reporting lens: Follow the buying process, not just the bill text.. Signature: Policy turns real when someone has to buy the system.
Article details
- Category
- Open Source AI
- Last updated
- April 11, 2026
- Public sources
- 12 linked source notes
Byline
Tracks the institutions, incentives, and market structure that quietly decide which AI systems get deployed and why.



