WildClawBench finds AI agents still fail real work
WildClawBench drops frontier models into messy OpenClaw workflows, and even the leaders finish barely half the job. That is a truer test than another polished demo.

 ainewssilo.com
ainewssilo.comWildClawBench matters because it treats AI agents like workers in a messy environment, and the best of them still come back with half the checklist undone.
Benchmarks usually arrive dressed for a victory parade. WildClawBench shows up in work boots.
That difference matters. The benchmark, published by the InternLM team, does not ask whether a model can call one clean tool or ace one neatly packaged prompt. It drops agents into a live OpenClaw environment with a real browser, real bash shell, real files, real email, and real calendar services, then asks them to do jobs that look suspiciously like the things people keep claiming agents can already handle. Clip video highlights from a football match. Negotiate a meeting over multiple rounds of email. Search through conflicting information. Write an inference script for an undocumented codebase. Catch a privacy leak before it gets expensive.
The result is not flattering. On the public WildClawBench leaderboard, every frontier model tested scores below 0.55 out of 1.0. Claude Opus 4.6 leads at 51.6 percent. GPT-5.4 is right behind at 50.3 percent. Then the field falls away. If you have been marinating in agent demos for the last year, this is the part where the soundtrack record scratches.
I like this benchmark more than most because it grades the messy middle of work. A polished demo can hide a lot. A broken workflow cannot.
what WildClawBench actually tests in an OpenClaw workflow
WildClawBench covers 60 original tasks across six categories: productivity flow, code intelligence, social interaction, search and retrieval, creative synthesis, and safety alignment. The task mix matters because it forces models to do more than produce plausible output. They have to plan, recover from failures, keep context straight, use tools in sequence, and avoid doing something reckless when the environment gets weird.
That is a much better stress test than the usual agent benchmark aquarium. Most benchmark setups still isolate one narrow capability. Can the model format a tool call correctly? Can it fill a JSON schema? Can it finish a short instruction chain? Useful, sure. But that is like grading a chef by asking whether they can crack one egg.
WildClawBench goes after the full job instead. The benchmark authors say each task runs inside its own Docker container with the same image, data, and grading code, and that the ground truth plus grader are injected only after the agent finishes. That design choice matters for credibility. It reduces leakage and makes reruns more meaningful. It is also why this project fits neatly beside our earlier piece on why AI benchmark wins feel less trustworthy. The more a benchmark exposes its machinery, the easier it is to take the score seriously.
The task examples are refreshingly unglamorous. One asks an agent to coordinate meetings across multiple participants by sending emails, checking calendars, resolving conflicts, and booking the slot. Another expects video understanding and highlight clipping. Another forces codebase comprehension with minimal hand-holding. These are not moon-shot AGI puzzles. They are assistant jobs, ops jobs, and coding chores. In other words, the exact territory where sales decks have been especially confident.
Claude Opus 4.6 vs GPT-5.4 in WildClawBench
Here is the part most readers want first, and fair enough.
| Model | Overall score | Avg time | Avg cost | Fast read |
|---|---|---|---|---|
| Claude Opus 4.6 | 51.6% | 508 min | $80.85 | Best overall, painfully expensive |
| GPT-5.4 | 50.3% | 350 min | $20.08 | Nearly tied, much cheaper |
| GLM 5 | 42.6% | 373 min | $11.39 | Strong third-place value |
| Gemini 3.1 Pro* | 40.8% | 240 min | $18.22 | Fastest of the top four, low-effort mode caveat |
| MiMo V2 Pro | 40.2% | 458 min | $26.47 | Competitive, slower than it looks |
| MiniMax M2.7 | 33.8% | 551 min | $7.47 | Cheapest model the authors call usable |
* The repository notes that Gemini 3.1 Pro was evaluated in low-effort mode, so this number should not be treated as its ceiling.

Two things jump out. First, the top of the table is surprisingly tight. Claude Opus 4.6 beats GPT-5.4 by just 1.3 points. Second, the price gap is not tight at all. According to the repo table, Opus cost about four times more than GPT-5.4 across the benchmark while taking longer on average. If you are choosing an agent model for actual deployment rather than for a screenshot, that detail is doing a lot of work.
This is why the benchmark is more useful than a simple win graphic. WildClawBench shows a market where “best” depends on what hurts more: failure rate, latency, or bill shock. Claude wins the crown. GPT-5.4 makes the better budget argument. GLM 5 looks like a serious value play. MiniMax M2.7 gets nowhere near the top, but its cost profile explains why cheaper “good enough” agents will keep finding buyers.
There is another interesting humiliation in the data. Even the leaders are not reliably finishing the kind of multi-step work that agent companies often market as if it were already routine. Fifty percent completion is not dominance. It is a reminder that frontier agents still spend a lot of time wandering the office with a clipboard, looking busy.
why scores below 0.55 are the useful part
A weak-looking leaderboard can be more informative than a strong one. That is what is happening here.
If every frontier model had landed in the 0.8 range, the benchmark would tell us less. Either the tasks would be too easy, the grading would be too forgiving, or the environment would not be messy enough to expose real failure modes. WildClawBench avoids that trap. The low ceiling suggests these tasks actually ask the models to survive long horizons, tool failure, shifting context, and multimodal work without a human quietly rescuing them off camera.
That is also why the benchmark lands at such a good moment. We are in the part of the agent cycle where the industry has stopped arguing about whether agents can act at all and started arguing about how to keep them useful, bounded, and supervised while they act. Our piece on the AI agent sandbox shift tracks the move toward constrained execution surfaces. Our piece on AI coding's new bottleneck: agent orchestration makes a parallel point from the workflow side. WildClawBench gives both arguments a hard number behind them.
The number is not “agents are bad.” The number is “end-to-end work is hard.” Big difference.
It also clarifies something people who run these systems already know in their bones. The last 30 percent of a job is where the chaos lives. The model found the right page, but clicked the wrong thing. The code almost ran, except one dependency broke and the agent handled it like a golden retriever carrying a wedding cake. The answer looked right, until a second source contradicted it. That is work. And it is exactly the part many tidy benchmarks politely ignore.
is WildClawBench a credible real world AI agent benchmark?
Mostly yes, and for reasons that are inspectable.
The benchmark has several credibility points in its favor. It uses a live OpenClaw environment rather than mocked tools. It publishes the dataset footprint on Hugging Face. It explains the task categories. It notes that results are averaged across multiple independent runs as of March 27. It documents reproducible containerized execution. Those are all good signs. They do not make the benchmark perfect, but they move it out of the “trust me, the bar chart is science” bucket.
There are still caveats. Sixty tasks is respectable, not universal. The tasks are hand-built by the benchmark authors, which means their own sense of what counts as important work shapes the test. That is unavoidable, but it matters. The benchmark is also OpenClaw-centric by design, so it is best read as a benchmark of agents operating in that style of environment rather than a final verdict on every agent product on earth. And because the repo notes that some prompts and scripts still explicitly reference OpenRouter, the setup is not yet a fully provider-neutral abstraction layer.
The leaderboard also needs to be read with normal caution. Gemini 3.1 Pro has a low-effort-mode disclaimer. Costs reflect this exact benchmark setup, not your future production bill. And a score gap of a point or two should not be treated like divine law when the systems themselves are still moving fast.
Still, the benchmark clears the bar that matters most to me: it gives builders enough visible method to argue with the result intelligently. That is a compliment. In 2026, invisible methodology is basically a request to be ignored.
what builders should do with this benchmark now
The first lesson is to stop treating agent deployments like a binary choice between “autonomous” and “not ready.” WildClawBench points to a messier middle. Plenty of useful value still exists below full completion. The trick is designing workflows that assume partial success, surface failure quickly, and keep humans close enough to catch the expensive mistakes.
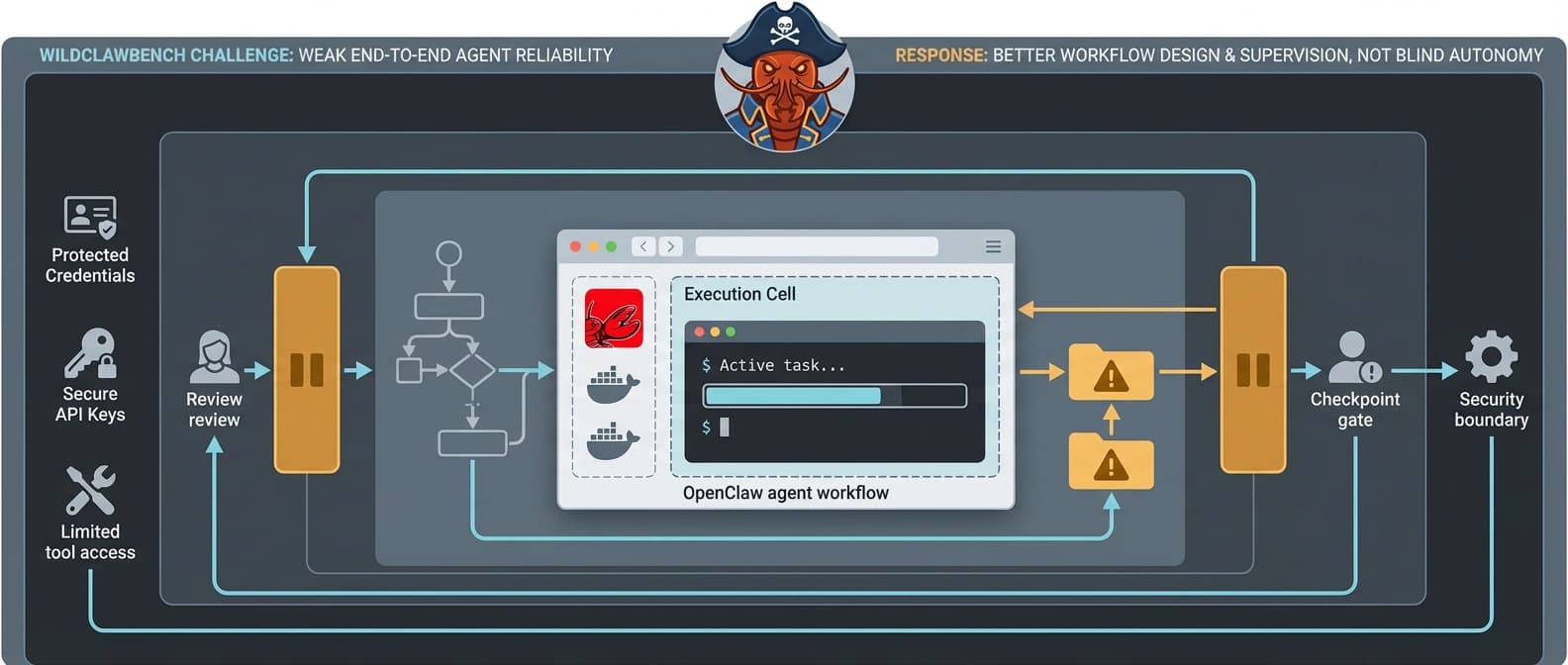
That means better boundaries. The more agents touch shells, files, browsers, and credentials, the more the winning teams will look like risk managers with decent product taste. Our story on NVIDIA OpenShell as agent security infrastructure matters here because the control plane is no longer a side issue. It is part of the product.
It also means better coordination layers. If one model struggles to finish an end-to-end coding task reliably, piling on more unchecked autonomy is not a strategy. More likely, the opportunity sits in routing, review, handoffs, and narrow specialization. That is one reason the recent push toward repo-native multi-agent systems, including our coverage of GitHub's repo-native multi-agent workflow, feels more believable than the old dream of one flawless super-agent doing everything.
And it means evaluating agents on finished work, not vibes. If your internal benchmark only tracks whether the model called the right tool, you are still measuring the easy part. WildClawBench is a useful reminder to score the whole workflow: planning, execution, recovery, verification, and safe completion.
My broader takeaway is simple. Frontier agents are real. They are also still unreliable enough that workflow design matters more than benchmark chest-thumping. WildClawBench does not kill the agent story. It upgrades it from demo theater to operations.
That is a healthier place to be.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Official benchmark site for the headline framing, leaderboard summary, task categories, and explanation of why the benchmark uses a live OpenClaw environment.
Core source for the benchmark README, exact leaderboard table, model cost and time data, category counts, Docker isolation details, and the note that results are averaged across multiple independent runs as of 2026-03-27.
Confirms the public dataset presence, heavy assets, workspace payload, and benchmark structure published alongside the site and repo.
Used for freshness details including repository creation on 2026-03-23 and metadata updated on 2026-04-06.
Used for dataset freshness details, public availability, and the public asset footprint behind the benchmark.

About the author
Maya Halberg
Maya writes across the AI field, from research claims and benchmark narratives to tools, products, institutional decisions, and market shifts. Her reporting stays focused on what changes once hype meets deployment, procurement, workflow reality, and human skepticism.
- 24
- Apr 11, 2026
- Stockholm · Remote
Archive signal
Reporting lens: Methodology over launch theater.. Signature: A result only matters after the setup becomes legible.
Article details
- Category
- AI Research
- Last updated
- April 11, 2026
- Lead illustration
- WildClawBench is useful because it grades agent systems inside messy, tool-heavy work, not in a clean benchmark aquarium.
- Public sources
- 5 linked source notes
Byline
Writes across the AI field with an eye for what survives contact with real users, real budgets, and real operating constraints.

