Qwen3.6-Plus pitches repo-scale coding agents
Alibaba pitches Qwen3.6-Plus as a 1M-context model for repo-scale coding agents. The real test is whether that yields calmer workflows, not prettier benchmark theater.

 ainewssilo.com
ainewssilo.comThe interesting Qwen3.6-Plus claim is not that it can talk about code. It is that Alibaba wants developers to trust it with the long, messy middle of the job.
Alibaba wants Qwen3.6-Plus to read less like a chatbot refresh and more like a foreman for messy software work. The pitch is simple: a 1M-token context window, stronger agentic coding, multimodal reasoning, repo-level engineering, and compatibility with the tools developers already use. That is more interesting than "here is another benchmark chart, please clap." It is also riskier, because execution claims are where vendors stop coasting on vibes and start asking to borrow your build pipeline.
I think the framing is smart. I also think it deserves a raised eyebrow. Repo-scale coding is not a synonym for "the model saw more files and felt ambitious." It means the agent can keep context straight, survive tool calls, recover after failure, and stay useful once the repository stops behaving like a stage-managed demo.
Why Qwen3.6-Plus is pushing the repo-scale coding claim
Repo-scale work means staying in the loop
In the main Alibaba Cloud launch post, Qwen3.6-Plus is presented as a hosted model built for long-horizon agent work: repository-level problem solving, terminal operations, automated task execution, and stronger multimodal perception. The companion press release makes the pitch even plainer by saying the model can plan, test, and iterate through frontend and repo-scale engineering tasks.
That is the important distinction. Alibaba is not merely saying Qwen3.6-Plus can talk about code. It is saying the model can stay inside the work loop long enough to move code forward. One is a talk show. The other has logs, tool failures, and a very real chance of breaking something expensive before lunch.
The canonical Qwen launch page and the team's same-day post on X reinforce the same message. The commercial story is not "we also have a smart model." It is "we have a model for actual execution." That is where the market wants to go, and where the market gets less forgiving.
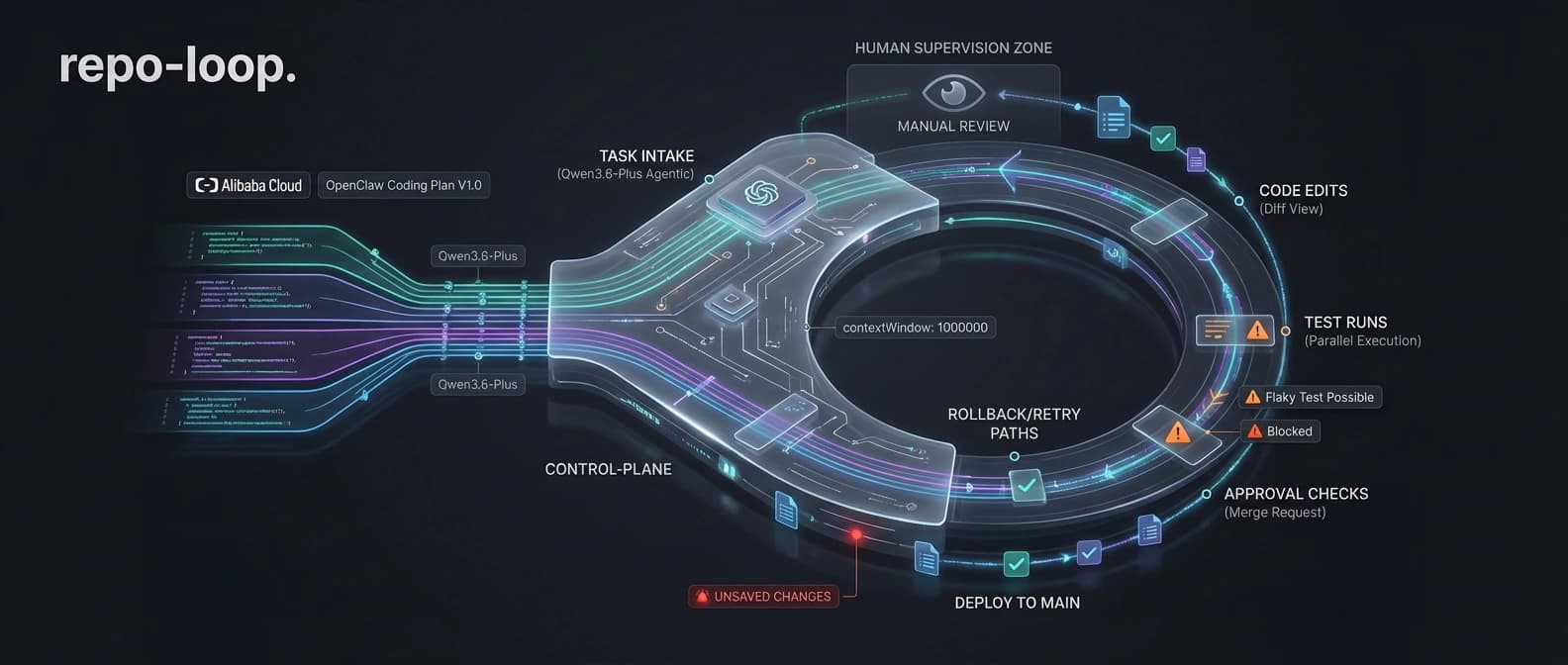
Why the Qwen3.6-Plus benchmark story still needs a raised eyebrow
QwenClawBench and QwenWebBench are interesting, not sacred
The benchmark section is extensive enough to qualify as furniture. Qwen3.6-Plus is stacked up against frontier models across coding work, terminal tasks, tool use, multimodal reasoning, long-context retrieval, and several internal scorecards, including QwenClawBench and QwenWebBench. The footnotes alone could make a normal person quietly close the tab and go outside.
Some of that detail is useful. At least Alibaba is showing its homework. But it is still launch homework. Internal benchmarks and custom scaffolds can tell you where a vendor believes its system is strong. They do not become field evidence because the tables are large and the footnotes look disciplined. If you need a broader refresher on that problem, our piece on benchmark trust recession remains annoyingly relevant.
I keep coming back to a duller test. Does the model keep a long software job coherent when a real repo starts fighting back? Benchmark cards rarely show the glamorous parts of agent work, such as weird project structure, ambiguous intent, stale tests, noisy tool output, and partial failure. They definitely do not show the special joy of a tool call that technically succeeded while still missing the point. Production has a way of removing the makeup.
Why the workflow implications matter more than the trophy shelf
The 1M context and preserve_thinking features target longer jobs
What caught my eye faster than the scoreboards was the API detail. Alibaba highlights preserve_thinking, an option meant to keep prior thinking content across turns for agentic tasks. That is not the kind of feature you advertise when your core use case is a one-shot answer in a pretty chat box. It is the kind of feature you add when you expect long, multi-step jobs where continuity matters and amnesia gets expensive.
Combined with the default 1M-token context window, the pitch becomes clearer. Alibaba wants Qwen3.6-Plus to handle long repo sessions, tool use, and iterative execution without constantly dropping the thread like a distracted contractor who insists the missing wall was probably decorative. That fits the broader shift we have been tracking in AI coding's new bottleneck: agent orchestration. Once teams move from "write me a function" to "own this task until the tests settle down," memory, tool discipline, and recovery start doing much more of the work.
Multimodal coding is the second half of the sales pitch
Alibaba is also trying to sell Qwen3.6-Plus as more than a terminal model. The launch post says the model can reason over documents, screenshots, prototypes, charts, and UI surfaces, then turn that understanding into code or action. That visual-coding angle matters because a lot of real engineering work now starts from a screenshot, a design reference, or a dashboard someone pasted into chat with the confidence of a person leaving a raccoon on your porch.
If Qwen3.6-Plus is genuinely better at turning visual context into usable frontend work, that gives it a wider lane than ordinary code completion. It also nudges the model closer to the agent-stack story we have seen elsewhere, including Microsoft Agent Framework as the unifying successor to older agent bets. The market keeps moving toward systems that can perceive, reason, and act inside one loop. Qwen is very obviously trying to occupy that lane.
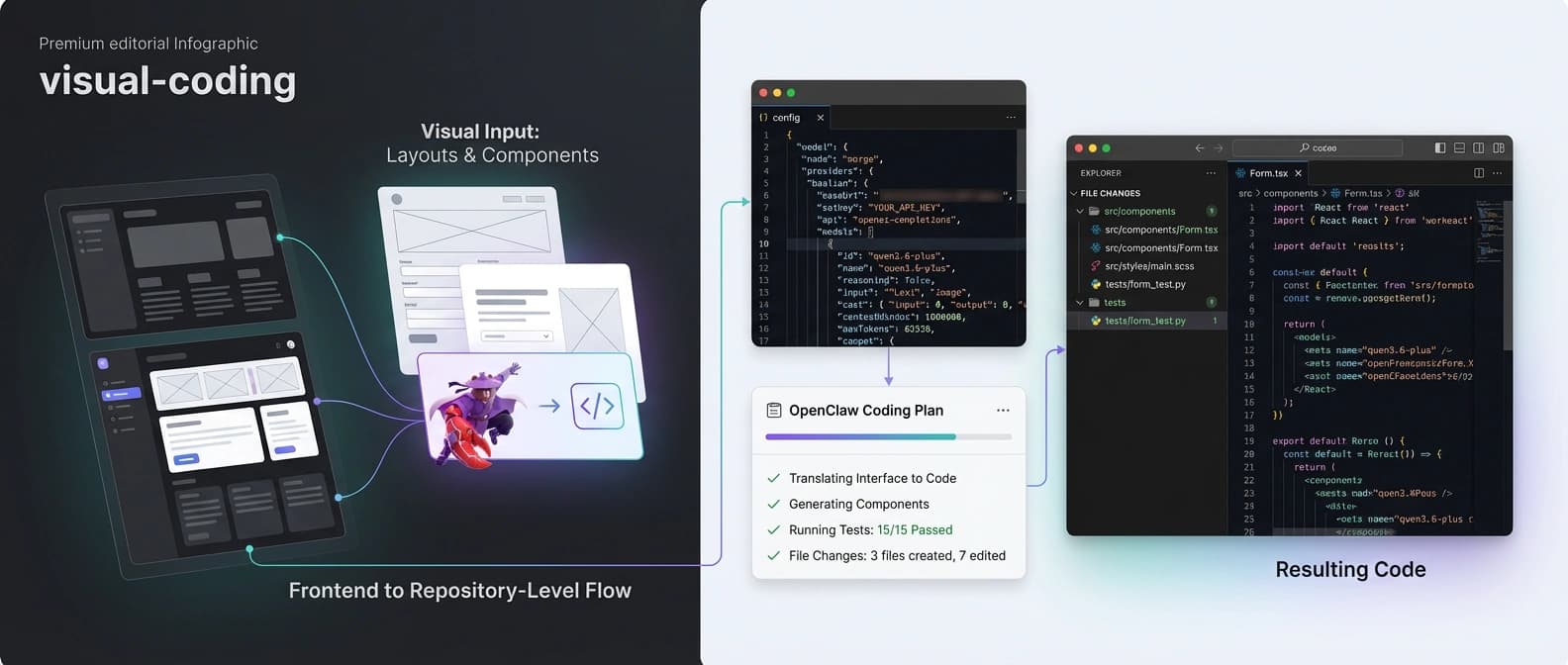
Where Alibaba is trying to win Qwen3.6-Plus adoption
OpenClaw and Claude Code support make this a distribution play
The most practical part of the package is not the benchmark spread. It is the compatibility story. Alibaba says Qwen3.6-Plus can plug into OpenClaw, Claude Code, Qwen Code, Cline, and OpenCode. The Model Studio OpenClaw documentation and the main launch post show the same strategy: meet developers where they already work, offer OpenAI-compatible and Anthropic-compatible surfaces, and make the model feel like a drop-in engine rather than a separate universe nobody asked for.
Developers rarely switch workflows because a vendor says "state of the art" three times in a row. They switch when the model can appear inside the tools, habits, and credentials they already tolerate. Manual config is not glamorous. It is paperwork wearing a cape. It is still how distribution happens.
This also explains the enterprise angle in the press release. Alibaba says Qwen3.6-Plus will feed into Wukong and the Qwen App, which makes the launch feel less like a lab flex and more like infrastructure positioning. If the model can sit underneath enterprise agent surfaces, coding tools, and multimodal app flows at once, the value is not only the model itself. It is the workflow gravity around it.
It is also worth saying what this launch is not. If your first question is whether you can inspect the weights, run the stack locally, or build on an open release, this is a different bargain from our earlier looks at Holo3's computer-use foothold in open weights or Gemma 4's on-device agent stack. Qwen3.6-Plus, at least in this form, is a hosted execution story.
What teams should test before trusting Qwen3.6-Plus with a repo
Start with failure recovery, not the happy-path demo
If I were evaluating Qwen3.6-Plus tomorrow, I would spend less time admiring the headline scores and more time running ugly workflow tests. Give it a medium-sized repo with mixed frontend and backend surfaces. Ask it to fix a bug, update tests, and adjust a UI state from a screenshot. Interrupt it halfway through, feed it a noisy tool result, and see whether it recovers cleanly or starts improvising like a manager caught pretending to understand Kubernetes.
The good version of this model will do four things well. It will keep state across long jobs. It will use tools without turning every task into a token bonfire. It will understand visual context well enough to change real interfaces. And it will fail in ways that are legible, not mystical.
The real bar is calmer execution
That is why Alibaba's marketing choice is smarter than a pure benchmark victory lap. By talking so aggressively about repo-scale coding agents, it is pointing people toward the right evaluation frame. The downside is that the bar becomes much higher. Once you say "real-world agents," nobody sensible is going to clap just because your custom harness liked the answers.
Qwen3.6-Plus may turn out to be very good. The launch materials suggest Alibaba understands where the market has moved: away from chat demos, toward models that can hold context, work through tools, and stay useful across longer software jobs. That is the right direction. Now it has to survive the boring part. It has to work in the repo, not just in the keynote. Software has a reliable way of checking whether the story was real or merely well dressed.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Canonical launch surface for Qwen3.6 and the cleanest statement of the model family positioning.
Core product post spelling out the 1M context window, coding-agent pitch, benchmark framing, multimodal claims, and tool compatibility.
Press-release framing that adds the enterprise deployment angle, Wukong, and Qwen App integration claims.
Same-day social framing that reinforces the repo-scale coding and multimodal launch message.
Practical documentation showing the OpenClaw integration path and the broader compatibility strategy for real developer workflows.

About the author
Maya Halberg
Maya writes across the AI field, from research claims and benchmark narratives to tools, products, institutional decisions, and market shifts. Her reporting stays focused on what changes once hype meets deployment, procurement, workflow reality, and human skepticism.
- 24
- Apr 11, 2026
- Stockholm · Remote
Archive signal
Reporting lens: Methodology over launch theater.. Signature: A result only matters after the setup becomes legible.
Article details
- Category
- AI Tools
- Last updated
- April 11, 2026
- Public sources
- 5 linked source notes
Byline
Writes across the AI field with an eye for what survives contact with real users, real budgets, and real operating constraints.



