Google adds Flex and Priority lanes to Gemini API
Google's Gemini API now sells traffic classes directly: Flex cuts costs for background agent work, while Priority buys speed and reliability for user-facing turns.

 ainewssilo.com
ainewssilo.comGoogle did not launch a new model here. It launched traffic management as a billable product.
Google's April 2 launch looks small if you only skim for model names. Flex and Priority are not new models. They are traffic classes. That sounds boring right up until you remember how most agent systems actually behave: one request is talking to a human who is waiting, and the next request is the agent wandering off to do paperwork.
That is the useful shift here. Google has added Flex and Priority inference tiers to the Gemini API so developers can push both kinds of work through the same synchronous surface by setting service_tier. If you have ever glued a user-facing copilot to a slower background chain, the pitch is obvious. Google is taking queue management that used to live in architecture diagrams and selling it back as a product feature.
Google turned urgency into an API parameter
The launch post frames the split cleanly. Flex is for latency-tolerant background jobs. Priority is for user-facing traffic that needs a faster, more reliable path. The important detail is that both sit on the normal synchronous Gemini API instead of forcing teams to split the world between standard calls and the asynchronous Batch API.
That matters because agent workloads are awkward in exactly the way batch systems dislike. A lot of them are sequential. Call N + 1 depends on the output of call N. The model thinks, browses, calls a tool, revises, calls another tool, and only then surfaces something useful. Batch is still fine for massive offline runs, but it is not built for that kind of chained improvisation. Agents are very good at generating chained improvisation.
Google's own docs now present the choice as three synchronous lanes. Standard remains the default. Priority routes traffic into high-criticality queues for lower latency and higher reliability. Flex routes it into opportunistic capacity for a 50 percent discount. Same API family, same request shape, same mental model. Just a new argument in the request body and, suddenly, the API starts behaving like an airline seat map.
There is a second, quieter change in that wording. Google is treating urgency as application data. The old question was, "Which endpoint should I send this to?" The new question is, "How important is this request, really?" That is a better fit for agents because a single workflow can contain both a sleepy background step and a very awake user-facing step. One support agent session might classify a ticket, search internal docs, summarize a thread, and then answer the user. Those sub-jobs do not all deserve the same queue.
Google also kept the interface friction low on purpose. The Flex docs show service_tier: 'flex'. The Priority docs show service_tier: 'priority'. Omit the field and you get Standard. That is not glamorous engineering theater. It is a tiny control that lets teams change economics and reliability without redesigning the whole app. The cookbook notebook drives the same point home: Google wants this to feel like a normal developer setting, not like a separate product that requires a migration project and three meetings.
This also fits the broader direction of Google's developer stack. We already saw Google make the Gemini API's tool combination and grounding flow feel more like a control plane, and we have watched AI Studio become a fuller distribution surface. Flex and Priority extend that logic. Google is not only selling model access. It is selling more knobs around how serious each request is allowed to be.
Flex is the cheap lane, not the fast one
Flex is the part I suspect operators will actually try first, because the offer is blunt. The optimization overview says Flex runs at 50 percent of Standard pricing. The dedicated Flex docs add the real caveats: it stays synchronous, targets 1 to 15 minutes of latency, counts toward general rate limits, and is explicitly sheddable if the platform gets busy.
That combination is the entire point. Flex is for work that is still sequential enough to be awkward in Batch, but not urgent enough to deserve a user-facing lane. Google names background CRM updates, offline evaluations, and sequential agent chains as the natural use cases. Those are not glamorous examples, but they are exactly where a lot of token spend quietly goes to die.
The most important word in the Flex docs may be "synchronous." Batch already gives a 50 percent discount, but it does it through a different operational shape: job submission, background processing, and patience. Flex is cheaper in a much more convenient way. You still make a normal call and still get a normal response. That matters when call N + 1 cannot start until call N finishes, which is the defining personality flaw of many agent chains.
The live pricing page makes the economics concrete. On Gemini 3 Flash Preview, Standard paid-tier pricing is listed at $0.50 per million input tokens and $3.00 per million output tokens for text, image, and video input classes. Flex drops that to $0.25 and $1.50. If your agent spends half its life doing background analysis, that is not a rounding error. That is the kind of line item that gets a product manager suddenly interested in inference architecture.
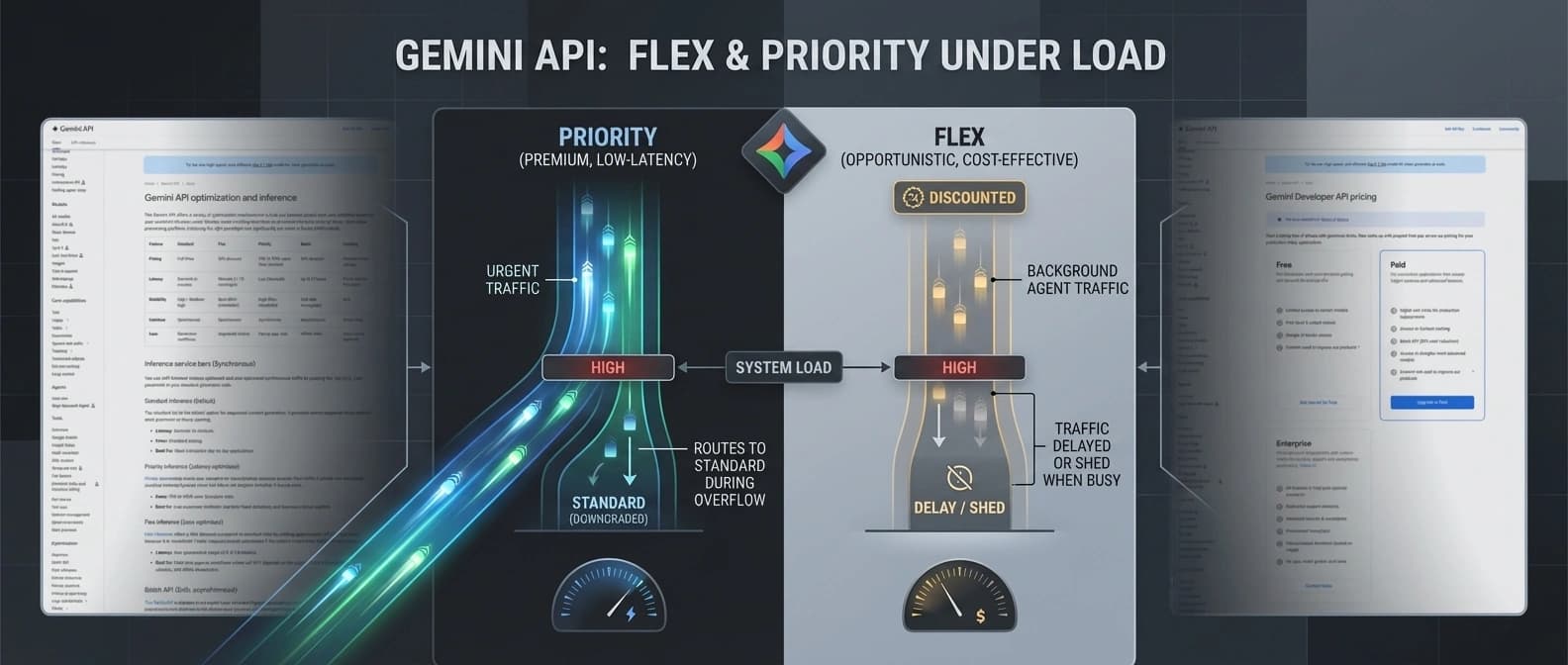
The catch is that Flex is not a cheap fast lane. It is a cheap maybe later lane. Google gives a target, not an SLA. If traffic spikes, Flex can be pushed aside. So this is not the setting for a live support bot or anything that has a human staring at a spinner and reconsidering their life choices. It is the setting for the part of the workflow nobody sees, as long as it finishes in time to still matter.
It is also the setting for a very specific kind of agent behavior that has been awkward to price until now: long-ish chains of model calls where latency matters eventually, but not immediately. Think enrichment, hidden research loops, internal ticket triage, or a multi-step planning phase before the app says anything to the user. Those jobs are too interactive for Batch, too numerous for Standard if you care about cost, and too unimportant for Priority. Flex exists for that gray area. Every platform eventually discovers that the gray area is where the invoices live.
Priority is the premium lane, but not a force field
Priority is the inverse deal. Google's optimization page describes it as latency-optimized, non-sheddable traffic with the highest reliability. The dedicated Priority docs say it sits above Standard and Flex traffic, but it is only available to Tier 2 and Tier 3 paid projects across GenerateContent and Interactions.
That access limit matters because Google is clearly treating Priority as a production-control feature, not a toy toggle. The pricing page also makes the premium explicit. In the same Gemini 3 Flash Preview table, Priority is listed at $0.90 per million input tokens and $5.40 per million output tokens. In other words, you are paying for the request to behave like it has manners.
The docs describe Priority as the highest-criticality queue, which is a much more useful phrase than the usual launch-language perfume. It tells you what Google is really selling: better odds when the platform is busy. That is a different promise from guaranteed capacity. It is business class, not a private jet.
There is, however, one very important caveat that keeps this from turning into marketing fantasy. Priority can still downgrade to Standard if you exceed dynamic Priority limits. Google surfaces that through the x-gemini-service-tier response header, which is exactly the kind of small operational detail that saves a team from lying to itself in production. Priority is premium routing, not divine protection.
That header matters more than it may look on first read. It gives teams a clean way to separate what they asked for from what they actually got. If you are using Priority for a customer-support agent, a time-sensitive moderation flow, or a live copilot turn, you want observability around downgrade behavior from day one. Otherwise the postmortem becomes a theological debate about whether the premium lane was ever premium in the moment that counted.
That makes Priority best suited to the turns that really are user-facing or time-sensitive: customer support, live copilots, moderation, fraud checks, and the sort of agent handoff where a delay is more expensive than the extra tokens. It also fits neatly beside Google's broader push around Gemini 3.1 Flash Live as a real-time agent rail. Once you are selling live interaction seriously, you need a story for which requests are allowed to cut the line.
Why this matters for agent teams now
What Google has really launched is a cleaner way to run mixed-criticality agent workloads without splitting them across entirely different products. An agent can do background research, summarization, or enrichment in Flex, then switch to Priority when it needs to answer a waiting user, all while staying on the same API surface and the same general programming model.
A simple example helps. Imagine a support assistant handling an incoming billing problem. The visible turn, where the user is waiting for a useful answer, is a good candidate for Priority. The hidden work behind it might not be. The assistant could search old tickets, summarize account history, classify the problem, and draft a few possible responses in Flex or Standard before spending premium routing only on the final answer or the live clarification step. That is a more sensible way to pay for agents than pretending every token deserves white-glove treatment.
That sounds modest, but it changes the conversation. Instead of asking only which model to use, teams can now ask which lane each step deserves. That is a more honest question. Not every token is sacred. Some of them are there to keep the app alive. Some are there because the agent is muttering to itself in the back office.
It also turns inference management into a clearer budget discussion. We have already covered how Google keeps pushing its stack outward into workflow and economics, whether through TurboQuant's inference-cost framing or the broader Gemini distribution story. Flex and Priority continue that pattern. The model is still the product, yes, but the queue is increasingly the business model.
There is also a practical architectural benefit here that is easy to miss if you read only the pricing rows. Standard does not disappear. It becomes the middle lane. That means teams can keep ordinary app traffic on Standard, move hidden background chains to Flex, and reserve Priority for the short list of turns where latency or reliability really matters. That is much cleaner than the old shape where "cheap" often implied "move this into a separate asynchronous system and pray the orchestration stays readable."
I think that middle-lane role for Standard is quietly important. Most production systems do not want a dramatic two-way split between bargain traffic and premium traffic. They want a normal lane for normal work, a thrift lane for things that can wait, and a premium lane for the few moments users actually notice. Google has basically built a three-class airline cabin for tokens. Which is funny, because airlines and cloud platforms both discovered the same truth years ago: once you can segment urgency, you can segment price.
That matters even more for teams building on one evolving Google surface. A company already using Gemini tools, grounding, or live flows does not have to treat this as a separate vendor decision. It can stay inside the same auth model, the same SDK family, the same observability story, and the same request pattern. For engineers, that means fewer weird adapters. For finance, it means cleaner cost attribution. For the poor soul on call, it means one less architecture diagram that looks like an accidental subway map.
There is a more strategic read too. Google could have told people to keep using Standard for user-facing work and Batch for everything slower. That would have been technically defensible and commercially less interesting. Instead, it created a synchronous low-cost lane for the gray area in between. That is an admission that agent workloads are producing a new kind of demand: work that is not interactive enough for premium service, not bulk enough for Batch, but still dependent and stateful enough that developers want a response in the same programming flow.
If that sounds niche, I would argue it is rapidly becoming normal. Research agents, support agents, coding agents, and internal copilots all generate these half-visible chains where the model is busy doing something useful but nobody needs an answer in the next two seconds. That work used to be awkward to schedule and awkward to price. Flex makes it easier to schedule. Priority makes it easier to justify paying more when the work really is urgent. Together they make the Gemini API feel less like a single pipe and more like a traffic system.
I also think the timing is revealing. Google launched this on April 2, then immediately backed it with docs, pricing tables, and a cookbook notebook. That is not the posture of a company treating traffic shaping as a footnote. It is the posture of a company that expects developers to operationalize it quickly. The message is almost blunt: stop treating all inference as one class of spend.
The caution is simple. Some Gemini 3.x rows on the pricing page are still preview, and the docs are fresh enough that details can move. So the exact tables should be treated like live infrastructure config, not sacred text carved into a mountain. But the product direction is already clear. Google thinks agent workloads deserve different traffic classes, and now it wants to charge accordingly.
That may be the most revealing part of the whole launch. Google did not just add cheaper inference and pricier inference. It admitted that modern agent systems are not one queue. Operators already knew that. Now the API does too.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Official April 2, 2026 launch post establishing the background-versus- interactive framing and the single synchronous-interface pitch.
Best source for Google's cross-tier comparison table covering Standard, Flex, Priority, Batch, latency targets, pricing deltas, and sheddability.
Confirms Flex remains synchronous, targets 1 to 15 minute latency, counts toward general rate limits, and is aimed at sequential background workflows.
Confirms Tier 2 and Tier 3 access, the graceful downgrade behavior, and the response header used to check which tier actually served the request.
Live pricing page showing the 50 percent Flex discount and the 75 to 100 percent Priority premium, including concrete per-model examples such as Gemini 3 Flash Preview.
Useful implementation proof that Google wants these tiers used in normal developer workflows rather than treated as a side feature.

About the author
Maya Halberg
Maya writes across the AI field, from research claims and benchmark narratives to tools, products, institutional decisions, and market shifts. Her reporting stays focused on what changes once hype meets deployment, procurement, workflow reality, and human skepticism.
- 24
- Apr 11, 2026
- Stockholm · Remote
Archive signal
Reporting lens: Methodology over launch theater.. Signature: A result only matters after the setup becomes legible.
Article details
- Category
- AI Tools
- Last updated
- April 11, 2026
- Public sources
- 6 linked source notes
Byline
Writes across the AI field with an eye for what survives contact with real users, real budgets, and real operating constraints.



