OpenAI's safety bug bounty is an agent-risk bounty
OpenAI's new Safety Bug Bounty matters because it pays for prompt injection, data exfiltration, and MCP-era agent abuse that classic bug bounties miss.

 ainewssilo.com
ainewssilo.comOpenAI is not just paying for broken software. It is starting to pay for broken agent behavior.
OpenAI launched a public Safety Bug Bounty on March 25. The boring version of that headline is "OpenAI has another bug bounty." The interesting version is that OpenAI is now willing to pay for a different class of failure.
In the launch post, the company says the new program complements its Security Bug Bounty by accepting issues that create meaningful abuse and safety risk even when they do not qualify as conventional security vulnerabilities. I read that as a public admission that some model-connected failures now belong in the same operational bucket as classic bugs, especially once agents can browse, hold sessions, call tools, and touch real systems.
That is the shift. OpenAI is not just paying for broken software. It is starting to pay for broken agent behavior.
The scope tells you what OpenAI is worried about
The scope list is the giveaway. OpenAI says it will accept third-party prompt injection and data exfiltration reports where attacker-controlled text can reliably hijack a victim's agent, including Browser, ChatGPT Agent, and similar products, into taking harmful action or leaking sensitive information. The company says the behavior has to be reproducible at least 50 percent of the time.
That is a very different posture from treating prompt injection as one more odd language-model quirk. It frames the issue as a reportable abuse path.
The rest of the scope keeps widening the aperture. OpenAI also lists agentic products performing disallowed actions on OpenAI's own website at scale, other harmful agent actions with plausible and material harm, proprietary information leakage, and account or platform integrity abuse such as bypassing anti-automation controls, manipulating trust signals, or evading suspensions and bans.

I would summarize the program this way: if an agent can be steered into leaking, acting, or crossing a boundary it should not cross, OpenAI wants to hear about it. That may sound obvious now. It was much less obvious when the industry still treated prompt injection like a weird note passed in class instead of the digital equivalent of a forged work order.
Why prompt injection looks different once agents can act
This is where the broader agent ecosystem matters. In our WordPress MCP write-capabilities piece, the important shift was that MCP stopped being harmless context plumbing once agents could move from reading to acting. The same logic applies here. A poisoned page is one thing. A poisoned page that can steer a browsing agent toward tool calls, data leakage, or privileged actions is a much bigger problem.
That is also why other vendors have started wrapping agents in real control surfaces. NVIDIA OpenShell is basically a bet that policy, routing, and sandboxing have to live outside the agent's own reach. DefenseClaw makes the same point from the security-stack side. Once the product can do things, the guardrails stop being decorative.
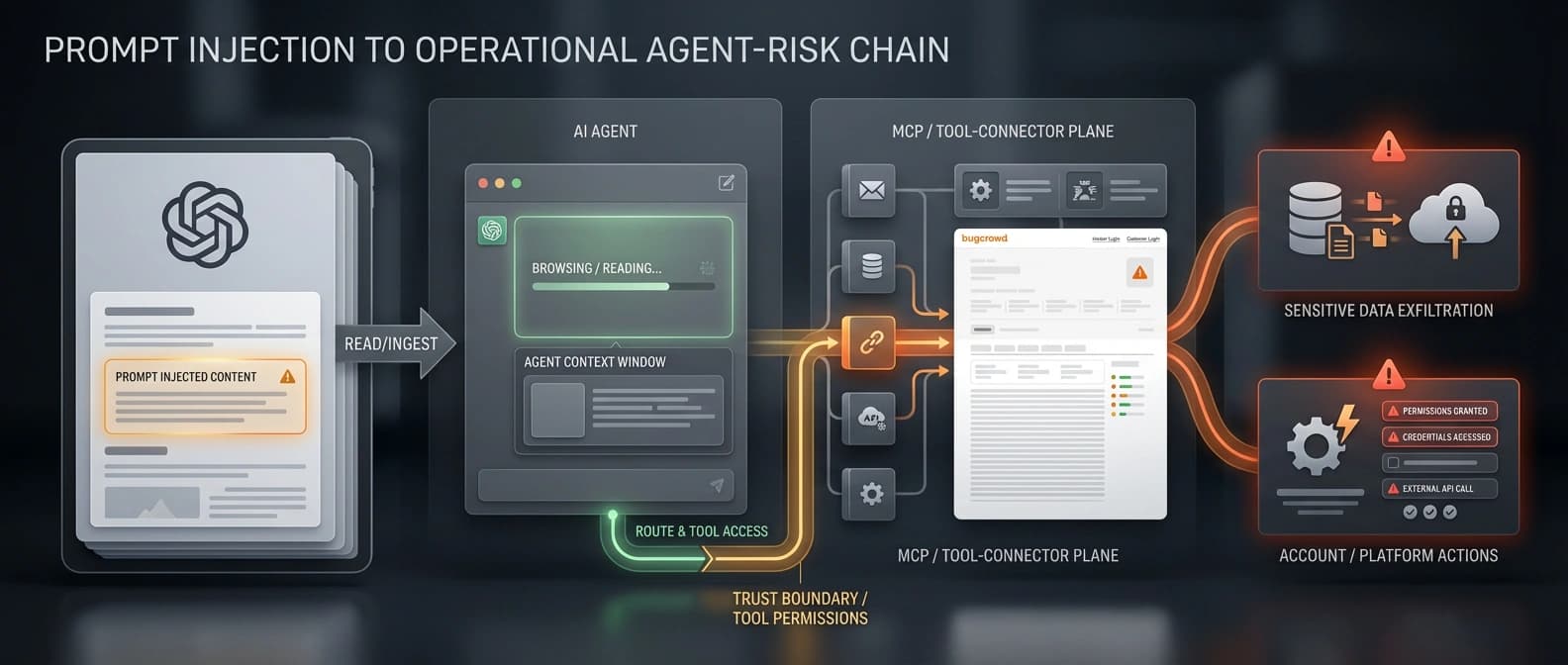
OpenAI's new bounty sits right inside that industry turn. It is a public way of saying that some of the most important failures in agent systems now come from boundary crossing: hostile content, tool misuse, proprietary leakage, trust-signal abuse, or session behavior that spills into the rest of the product. A chatbot saying something foolish is embarrassing. A tool-using agent doing it with live access is an incident report with better typography.
What OpenAI is deliberately leaving out
The exclusions matter almost as much as the scope. OpenAI says jailbreaks are out of scope for this program. General content-policy bypasses without demonstrable safety or abuse impact are out too. If the model becomes rude, weird, or merely unhelpful, that does not qualify. Frankly, that is probably wise. Otherwise the triage queue would become a museum of screenshots.
The carve-out tells me OpenAI is trying to draw a line between broad model-behavior complaints and narrower failures that create a concrete path to harm with a fixable boundary. The company even points researchers toward separate, harm-specific campaigns, such as its earlier bio bug bounty, when the issue is a scoped jailbreak problem rather than a public agent-abuse defect.
That discipline matters. It keeps the program focused on reproducible abuse chains rather than turning it into a paid inbox for every strange chat transcript on the internet. If you can show prompt injection, data exfiltration, harmful agent action, proprietary leakage, or account-integrity abuse with material impact, you are in the conversation. If you have generic model weirdness, you are not.
Why this will matter beyond OpenAI
The bigger signal is not just about one company. It is about what the market is slowly starting to recognize as a real defect class.
For years, prompt injection lived in an awkward category: obviously bad, frustratingly common, and easy for companies to treat as an inevitable property of language models. That posture gets much harder to maintain once models sit inside browsers, tools, sessions, and MCP-shaped workflows. At that point, the failure is not academic. It has side effects.
OpenAI's program does not solve the problem. What it does do is attach money, triage, and official language to it. Bug bounties are one of the clearest ways a platform says, "yes, this counts, and yes, we expect outside researchers to go find it." If more vendors follow, prompt injection and tool abuse will stop looking like fuzzy red-team folklore and start looking like ordinary engineering debt, just with stranger reproduction steps.
That is why I think this launch matters. Not because OpenAI added another web form. Because it answered a more important question in public: what kinds of AI failure now count as bugs serious enough to pay for? On this evidence, the answer is getting much more operational.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Core source for the March 25, 2026 launch, the in-scope agentic abuse categories, the prompt-injection and data-exfiltration language, the MCP note, the account-integrity scope, and the jailbreak carve-out.
Confirms the post appeared in OpenAI's news index on March 25, 2026 and keeps the freshness window anchored to the live company feed.
Useful context for how OpenAI now frames safety-and-abuse findings alongside traditional security reporting.
Use only to support the contrast that jailbreak-style harms still live in separate, private or scoped campaigns rather than in the new public Safety Bug Bounty.

About the author
Talia Reed
Talia reports on product surfaces, developer tools, platform shifts, category shifts, and the distribution choices that determine whether AI features become durable workflows. She looks for the moment where a launch stops being a demo and becomes an ecosystem move.
- 34
- Apr 1, 2026
- New York
Archive signal
Reporting lens: Distribution is usually the story hiding inside the launch.. Signature: A feature matters when it changes someone else’s roadmap.
Article details
- Category
- AI Products
- Last updated
- April 11, 2026
- Public sources
- 4 linked source notes
Byline
Covers product surfaces, tools, and the adoption moves that turn AI features into durable habits.




