TorchTPU gives PyTorch a straighter path to TPU pods
Google's new TorchTPU stack gives PyTorch teams a more native route into TPU training and serving through eager execution, torch.compile, and MPMD-aware distributed support.

 ainewssilo.com
ainewssilo.comTorchTPU matters because Google is finally pitching TPUs to PyTorch teams as a runtime they can approach more like PyTorch, not as a side quest in framework diplomacy.
Google's April 7 TorchTPU reveal is interesting for one practical reason: it tries to solve a problem PyTorch teams actually have. Plenty of organizations like TPU economics, TPU scale, or TPU adjacency to Google's own infrastructure. Fewer enjoy rewriting half a training stack just to get there.
That mismatch has been hanging over TPUs for years. "You can keep your PyTorch" has often sounded a bit like a landlord saying you can keep your furniture, provided you also rebuild the staircase. TorchTPU is Google's attempt to make that staircase less theatrical.
The company is pitching TorchTPU as a way to run PyTorch more natively on TPU hardware by starting with familiar tensors, keeping eager execution, and then offering a direct torch.compile path into XLA through StableHLO when teams want more performance. If that works in the field, it changes the TPU evaluation story. If it only works in launch diagrams, it becomes another engineering bridge that ends three meters before the river.
Google gives enough technical detail here to separate real progress from brochure copy.
TorchTPU targets a real PyTorch-to-TPU migration problem
The core TorchTPU pitch is not subtle. Google says a developer should be able to take an existing PyTorch script, initialize to tpu, and run the training loop without changing core logic. That is the aspiration, and it is smart positioning, but it should not be read as a universal zero-work migration promise. Hardware differences, distributed quirks, and model-shape choices still exist. TPU adoption has not been converted into a one-line lifestyle upgrade.
Still, the goal matters because it tells you what Google thinks was wrong with the old experience. The pain was not merely performance. The pain was that TPU support could feel like a translation layer first and a PyTorch workflow second.
TorchTPU tries to reverse that order.
Google built it on PyTorch's PrivateUse1 interface so the system can work with ordinary PyTorch tensors rather than wrappers or special subclasses. That is a small sentence with big consequences. The closer the runtime feels to stock PyTorch behavior, the easier it is for teams to test TPU fit before committing to a larger porting effort.
The timing makes sense now. Google needs TPUs to be legible to a much larger slice of the PyTorch world as training and serving sprawl across big clusters and mixed software stacks. We have seen similar pressure elsewhere, including NVIDIA's attempt to become the shared control plane around open model development in our piece on the Nemotron Coalition.
TorchTPU eager modes explain why the usability story might stick
The most interesting design choice in the TorchTPU post is Google's "Eager First" philosophy. That is a far better starting point than demanding an immediate full-graph compile detour every time a developer wants to see whether the thing runs.
Google describes three eager modes.
| TorchTPU mode | What it does now | Why an operator would use it |
|---|---|---|
| Debug Eager | Dispatches one op at a time and synchronizes with the CPU after every execution | Slow, but useful for finding shape mismatches, NaNs, and memory blowups before they become folklore |
| Strict Eager | Keeps single-op dispatch but runs asynchronously so CPU and TPU can progress together until sync points | Closest to familiar default PyTorch behavior when you are validating correctness without squeezing everything yet |
| Fused Eager | Reflects over the op stream and fuses steps into denser chunks before handing work to the TPU | The practical performance mode, with Google claiming 50% to 100+% gains over Strict Eager |
That middle-to-fast progression is important. It gives teams a workflow that starts with correctness, moves into something recognizably PyTorch-like, then graduates to better TPU utilization without requiring users to manually restage their whole program around compilation from the first minute.
Google says all three modes share a compilation cache that can operate on one host or persist across multi-host setups. That sounds unglamorous, which is exactly why it matters. Compilation overhead is one of those costs everybody hates and nobody advertises until the cluster is already booked.

If you are comparing this to the broader Google AI stack story, it is almost the opposite of the friendlier product pitches around things like Gemini 3's agent stack or the device-centric launch language around Gemma 4 in Android Studio. TorchTPU is not trying to charm you with an app. It is trying to convince infra teams they can debug first and optimize second. Frankly, that is more believable.
Torch.compile, XLA, and StableHLO are the real performance path
The eager story gets TorchTPU in the door. The compiler path is where Google wants to win the serious workloads.
For full-graph compilation, TorchTPU integrates with torch.compile. Google says it captures the FX graph with Torch Dynamo, then routes that graph into XLA instead of Torch Inductor. The handoff goes through StableHLO, the tensor IR that connects PyTorch operators to XLA's lowering path.
This choice is not surprising, but it is strategically revealing. Google is not pretending it found a cooler replacement for XLA. It is leaning into XLA as the battle-tested backend for TPU topologies, especially where dense compute and collective communication need to overlap well across the inter-chip interconnect. That is the exact sort of detail operators care about, and the exact sort of detail glossy launch recaps tend to skip because it ruins the clean gradient background.
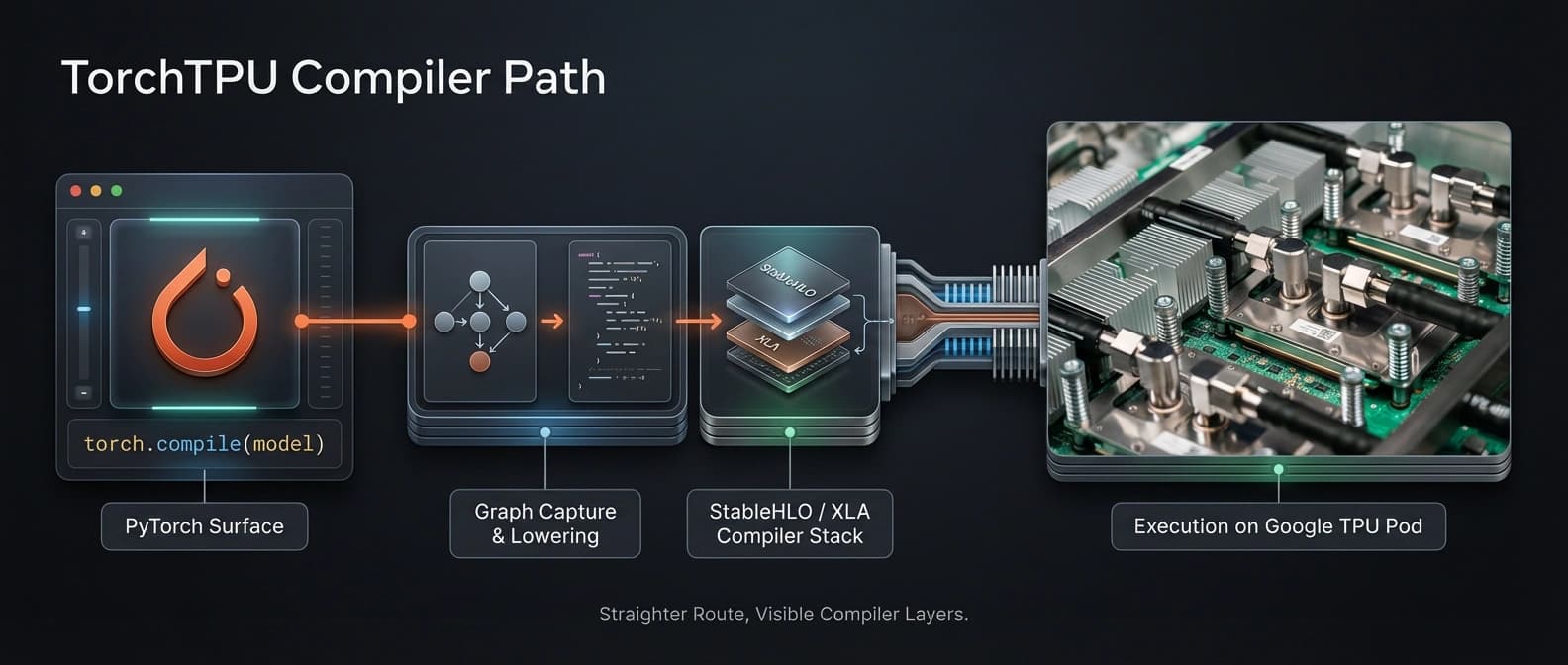
The article also makes a stronger claim than "we support compile." It says the eager and compiled paths reuse execution logic, which matters for migration confidence. If the compile path feels like an entirely different runtime universe, teams will treat it as a separate product. Reusing execution paths lowers that psychological bill.
Custom kernels are another sign Google is aiming above a demo-tier backend. TorchTPU already supports custom kernels written in Pallas and JAX via @torch_tpu.pallas.custom_jax_kernel. That is a meaningful extension point for engineers who need low-level hardware control. But Google is careful about what is and is not present. Helion support is still in progress. So is broader ecosystem integration. That distinction deserves to stay sharp.
TorchTPU vs PyTorch/XLA: what actually feels new
The most publishable comparison in the source is not TorchTPU versus GPUs. It is TorchTPU versus older PyTorch/XLA expectations.
Google explicitly describes PyTorch/XLA as a predecessor and points to a major limitation: pure SPMD assumptions. In practice, many PyTorch jobs contain slight rank divergence. Rank 0 logs. One process handles side effects. Somebody always does one extra weird thing because reality refuses to be a clean whitepaper.
That is where TorchTPU sounds materially different.
| Question | Older PyTorch/XLA expectation in Google's telling | TorchTPU position now |
|---|---|---|
| Default feel | More compile-centric and less natively PyTorch-like | Starts from ordinary PyTorch tensors and eager execution |
| Distributed purity | Best with pure SPMD behavior across ranks | Designed to tolerate some divergent executions and isolate communication where needed |
| Scaling APIs | Worked, but with stricter behavioral assumptions | Supports DDP, FSDPv2, and DTensor out of the box, according to Google |
| Operator extension | Less clearly pitched around PyTorch-native custom kernel flow | Supports Pallas and JAX custom kernels today |
| Migration tone | Often felt like adapting to TPU expectations first | Markets itself as keeping more of the PyTorch workflow intact |
That does not mean PyTorch/XLA is obsolete everywhere, nor does it mean every distributed edge case is solved. It means Google is finally describing the problem the way PyTorch users describe it themselves: distributed training is messy, and a backend that only likes perfect SPMD manners will spend a lot of time disappointed.
That part made me trust the post more. Large infrastructure launches usually pretend the real world is cleaner than it is. Here Google more or less admits that rank 0 still has opinions.
Distributed TPU jobs are where TorchTPU gets serious
Google says TorchTPU supports Distributed Data Parallel, Fully Sharded Data Parallel v2, and DTensor out of the box. It also says many third-party libraries built on PyTorch distributed APIs have been validated unchanged on TorchTPU. If that proves durable, it is a bigger story than the device-name change to tpu.
Why? Because once workloads move beyond a single accelerator, migration cost stops being about syntax and starts being about behavior. The whole point of TPUs is scale. Google frames modern model infrastructure as spanning thousands and even O(100,000) chips. At that size, the runtime is not just executing math. It is coordinating a social event for tensors, and those events go badly when one guest decides to improvise.
TorchTPU's answer is an MPMD-aware design that preserves correctness by isolating communication primitives when divergent execution appears, while still trying to preserve XLA's global optimization advantages. That is exactly the kind of compromise an operator wants to hear: not "we abolished distributed weirdness," but "we know it exists and we are fencing off the dangerous parts."

This is also why the post is stronger as infrastructure reporting than as a shiny product announcement. The interesting claim is not that TPUs are good. We know Google likes TPUs. The interesting claim is that Google now seems more willing to meet PyTorch developers where their code already lives, instead of asking them to become better citizens of an alternate runtime republic.
What ships now in TorchTPU, and what is still roadmap
Google does readers a favor by separating current support from the 2026 roadmap. That should not be optional in infrastructure launches, yet here we are.
| Status | TorchTPU capability |
|---|---|
| Available now, per Google | PrivateUse1-based native tensor integration, Debug/Strict/Fused Eager modes, shared compilation cache, torch.compile integration through Torch Dynamo into XLA via StableHLO, support for DDP/FSDPv2/DTensor, and custom kernels through Pallas and JAX |
| Roadmap for 2026 | Public GitHub repository, Helion integration, first-class dynamic shapes through torch.compile, native multi-queue support, deeper vLLM and TorchTitan integration, and validated linear scaling to full pod-size infrastructure |
That table is the difference between a useful article and launch-confetti recycling.
It means you should not say TorchTPU is fully open-sourced today. You should not say vLLM or TorchTitan support is already there unless a newer source confirms it. You should not treat dynamic shapes, multi-queue support, or Helion as current shipping features. And you should definitely not translate "roadmap" into "works perfectly by the time procurement signs."
The current shipping set is still significant. Training and serving support today, eager execution modes, the compile path, and distributed API support are enough to make TorchTPU a real infrastructure story now. The roadmap simply explains where Google still sees friction.
More native does not mean hardware reality disappears
One of the smartest parts of Google's post is also one of the least marketable: TPU hardware awareness still matters.
Google points to a concrete example. Many models hardcode attention head dimensions of 64, while current-generation TPUs hit peak matrix-multiplication efficiency at 128 or 256. In other words, a nicer runtime does not repeal physics. It just gets you to the point where hardware tuning is worth doing.
That is an important operator message because it keeps TorchTPU in bounds. The stack is promising if you want less rewiring and a more legible path from PyTorch to TPUs. It is not a promise that TPU optimization becomes unnecessary, or that every model architecture instantly lands on TPU in its final best form. You still have to care about the chip. Sorry. The silicon remains stubbornly physical.
This is where the announcement lines up with another piece of Google's recent developer messaging, including more edge-focused work like Google AI Edge's offline dictation push. The company increasingly wants developers to treat hardware-specific adaptation as an optimization phase rather than an entry barrier. That is a much better sales pitch, and sometimes even a true one.
Should PyTorch teams take TorchTPU seriously now?
Yes, with adult supervision.
TorchTPU looks meaningful because Google is solving the right problem in the right order. First, make TPU execution feel more like PyTorch through eager execution and ordinary tensors. Then offer a clear compiler path through torch.compile, StableHLO, and XLA. Then handle the ugly distributed edge cases that real PyTorch jobs bring with them. That is a coherent architecture story, not just a list of compatibility slogans.
I would not treat it as proof that TPU migration is suddenly effortless. I would treat it as proof that Google understands why many PyTorch teams stayed away, and has started building the bridge where those teams were actually standing.
The next six months matter. If Google ships the public repo, lands dynamic-shape work cleanly, expands ecosystem integrations, and shows convincing scaling evidence on full pod deployments, TorchTPU could turn TPUs into a much more plausible destination for PyTorch-first organizations. If not, it risks becoming one more elegant explanation for a workflow that operators still cannot quite trust under pressure.
For now, the bottom line is simpler. TorchTPU is not a benchmark parade. It is a migration ergonomics story, and a fairly good one.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Primary source for TorchTPU's eager modes, PrivateUse1 integration, torch.compile path through XLA and StableHLO, distributed support, hardware-awareness notes, and the 2026 roadmap.
Background reference for the intermediate representation Google says TorchTPU maps PyTorch operators into before XLA lowering.
Supports the custom-kernel section of Google's TorchTPU description, where Google says Pallas and JAX kernels are already supported.
Baseline PyTorch distributed API reference for the DDP support Google says TorchTPU handles today.
Background reference for the DTensor support Google lists as available out of the box in TorchTPU.
Official hub Google points readers to for continuing TorchTPU updates and TPU development materials.

About the author
Lena Ortiz
Lena tracks the economics and mechanics behind AI systems, from serving architecture and open-weight deployment to developer tooling, platform shifts, product decisions, and the operational tradeoffs that shape what teams actually run. Her reporting is aimed at builders and operators deciding what to trust, adopt, and maintain.
- 24
- Apr 10, 2026
- Berlin
Archive signal
Reporting lens: Operating leverage beats ideological posturing.. Signature: If the cost curve moves, the product strategy moves with it.
Article details
- Category
- AI Infrastructure
- Last updated
- April 11, 2026
- Public sources
- 6 linked source notes
Byline
Covers the economics, tooling, and operating realities that shape how AI gets built, shipped, and run.




