Netflix VOID model removes the object and the aftermath
Netflix has released VOID, a video-editing model that removes objects and their physical aftermath, but using it still means masks, two passes, and 40GB-plus VRAM.

 ainewssilo.com
ainewssilo.comThe clever part is not deleting the person. It is deleting the trouble they caused.
Netflix has publicly released VOID, and it is one of those rare model drops where the interesting part is not a shinier demo clip. It is the causal mess underneath. VOID is a video-editing model that removes an object from a scene and tries to remove the physical interactions that object caused, according to the Hugging Face release, GitHub repo, project page, and paper.
That sounds small until you picture the standard failure mode. Normal video object removal is pretty good at patching over the space where something used to be. Shadows, reflections, missing background, fine. But if you remove the person who was holding the guitar, a normal system often leaves the guitar floating there like it has hired its own lawyer. VOID is trying to fix that part too.
I find that more interesting than yet another generic video-model launch. This is not a consumer Netflix feature wedged between "Skip Intro" and "Next Episode." It is a public research release with code, checkpoints, a demo Space, and a Colab notebook. Public, yes. Easy, no.
What the Netflix VOID model actually does
The core pitch is interaction-aware deletion. The paper says existing methods handle appearance-level cleanup, but they fall apart when the removed object had meaningful physical effects on the scene. VOID is built for those cases. Remove the object, then update the downstream action so the shot still behaves like the world remembers gravity.
Physics keeps receipts.
The project page gives a simple example: if you remove a person holding a guitar, VOID also removes the person's effect on the guitar, so it can fall naturally instead of hanging in the air like a continuity error with attitude. The GitHub samples make the same point with smaller scenes, like a lime falling on a table or a ball rolling after another object disappears.
That difference matters because ordinary inpainting is a bit like repainting the wall after you remove a picture frame. VOID is trying to repaint the wall and explain why the vase never got knocked off the shelf. That is a much harder job, and also a much more useful one if video editing models are supposed to do more than cosmetic cleanup.
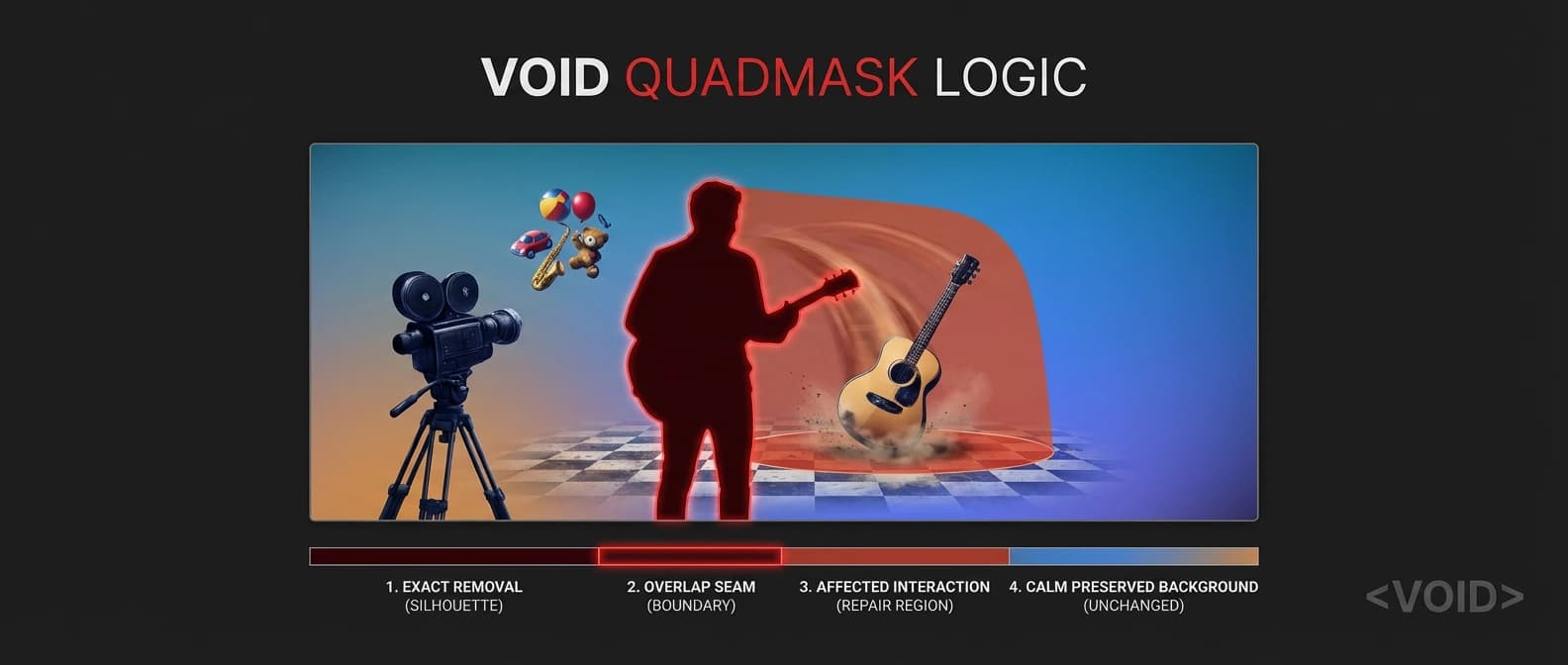
Why Netflix VOID video object removal is different
The clever mechanism is the quadmask. Instead of the usual "delete this blob and pray" setup, VOID uses four values: the primary object to remove, overlap regions, affected regions, and background to keep. The Hugging Face model card and GitHub repo spell this out clearly.
That affected-region lane is the whole story. During inference, a vision-language step identifies what else in the frame should change because the object is gone. The repo's mask pipeline uses SAM2 for segmentation and Gemini for reasoning about those interaction-affected regions. In other words, the model is not just painting over pixels with a larger mop. It is getting a structured hint about where causality spread through the scene.
I would not oversell that into "the model understands physics" because that is how you end up back in the swamp described in our piece on benchmark trust recession. But it is a real step beyond standard object erasure. The system is being trained to generate a counterfactual video, not merely a cleaner patch.
How to use the Netflix VOID model right now
The good news is that this is a genuine public package. As of April 4, the release surfaces are live across Hugging Face, GitHub, the project page, a demo Space, and a Colab notebook. That is already more useful than a paper with a Vimeo link and a prayer.
The less-good news is the hardware bill. The quick-start notebook says it requires a GPU with 40GB+ VRAM, with an A100 given as the example. So yes, it is public. It is just public in the way a professional pizza oven is public: you can absolutely use it if you happen to own the restaurant.
The easiest route is the notebook, but the full workflow is still fairly serious. You install dependencies, download the base CogVideoX-Fun-V1.5-5b-InP model plus VOID's checkpoints, prepare a source video, generate a quadmask, and provide a prompt describing the scene after removal. If you want the full mask pipeline, the repo also expects SAM2 and a Gemini API key for the reasoning stage.

Netflix VOID model limits: 40GB VRAM, masks, and two passes
This is where the launch stops sounding magical and starts sounding honest, which I appreciate. VOID has two checkpoints. Pass 1 is the base inpainting model and is enough for most videos. Pass 2 is optional and uses optical-flow-warped latent initialization to improve temporal consistency on longer clips or clean up morphing artifacts. That is smart engineering, but it is still a two-step workflow, not a magic eraser.
There are other limits too. The default resolution is 384x672, max length is 197 frames, and the training setup described in the release used 8x A100 80GB GPUs. The repo also notes that licensing constraints prevent Netflix from shipping the prebuilt training data, so it releases the data-generation code instead. This is a serious research package, not a frictionless creator app.
That does not make the release less important. If anything, it makes it more useful for the people who actually care about reproducibility and access, which is the same practical frame we keep coming back to in open-weight inference economics. A public package with annoying constraints is still far more valuable than a glossy demo nobody can inspect.
One caution is obvious and worth saying plainly: cleaner video object removal also sharpens misuse risk. Better deletion tools make it easier to falsify scenes, not just tidy them. So the real upside of a public release is not "problem solved." It is that researchers and developers can inspect the method, test limits, and argue about safeguards in the open instead of squinting at a teaser trailer.
The bottom line is not that Netflix has built the next Sora. It has done something narrower and, honestly, more interesting. VOID tries to remove the shove, not just the shover. For video editing, that is a real leap.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Confirms the public model release, quick-start notebook, 40GB-plus VRAM guidance, quadmask format, and the two-pass checkpoint structure.
Main implementation source for setup, SAM2-plus-Gemini mask pipeline, quadmask semantics, inference commands, and optional manual refinement.
Best concise explanation of the method, especially the causal interaction angle and the optional second pass for morphing artifacts.
Paper abstract anchors the main claim: VOID targets physically plausible counterfactual video editing, not standard appearance-only removal.
Confirms there is a public demo surface associated with the release.
Confirms there is a public notebook entry point for trying the released project, even though the hardware requirement remains heavy.

About the author
Idris Vale
Idris writes about the institutional machinery around AI, but the lens is broader than policy alone: procurement frameworks, public-sector buying rules, platform leverage, compliance burdens, workflow risk, and the market structure hiding beneath product or infrastructure headlines. The through-line is practical power, not abstract theater.
- 23
- Apr 10, 2026
- Brussels · London corridor
Archive signal
Reporting lens: Follow the buying process, not just the bill text.. Signature: Policy turns real when someone has to buy the system.
Article details
- Category
- Open Source AI
- Last updated
- April 11, 2026
- Public sources
- 6 linked source notes
Byline
Tracks the institutions, incentives, and market structure that quietly decide which AI systems get deployed and why.



