GitHub makes Copilot training opt-out for individuals
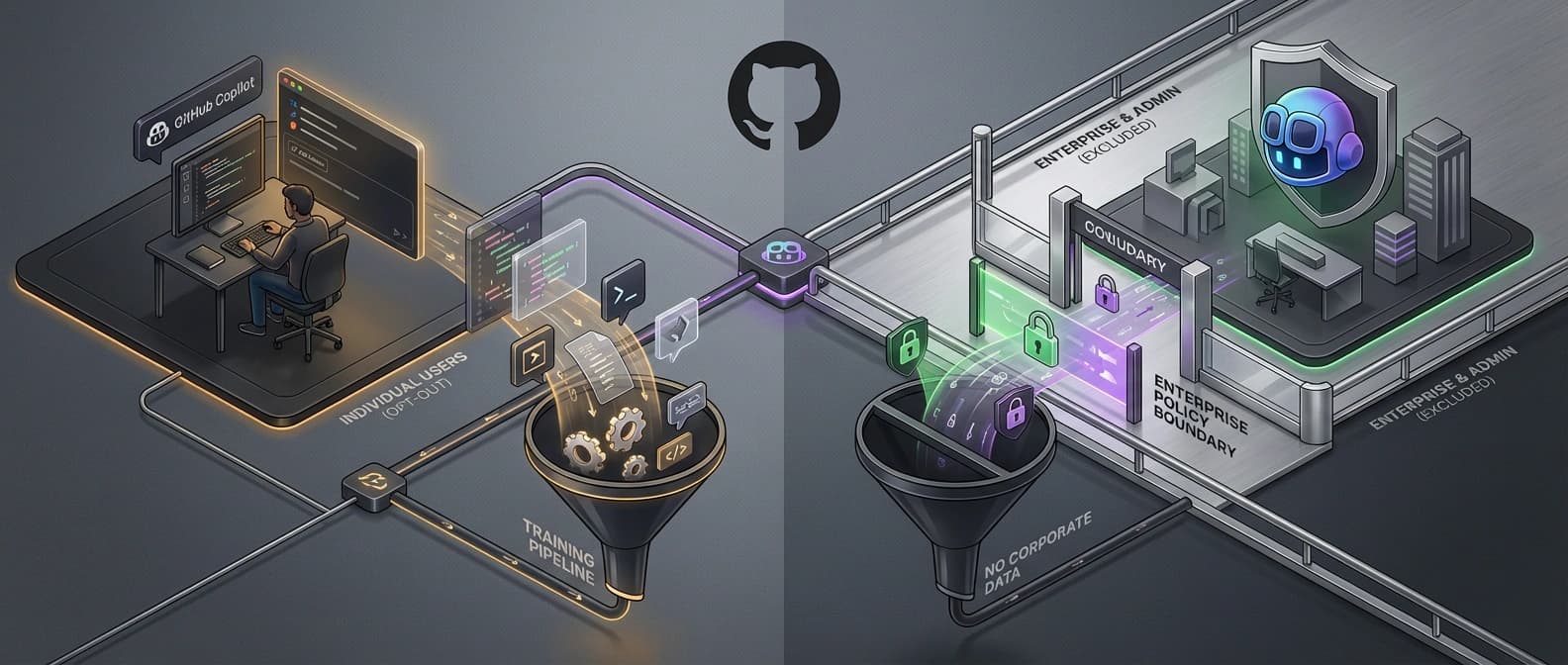
GitHub now trains on Copilot interaction data from Free, Pro, and Pro+ users by default, while Business and Enterprise accounts stay outside the training pool.
 ainewssilo.com
ainewssilo.comGitHub is not just tweaking Copilot's settings. It is changing the default bargain for solo developers.
GitHub is not announcing that it will hoover up every private repository on earth and feed the whole lot into a training run like a Roomba with a law degree. That is the cartoon version, and it is not what the policy says.
The real change is narrower, and more important. Starting April 24, GitHub says it will use Copilot interaction data from Copilot Free, Pro, and Pro+ users to train and improve its AI models unless those users opt out. That interaction data can include prompts, outputs, code snippets, and the surrounding context Copilot sees while you are using it. Copilot Business and Copilot Enterprise are excluded.
That is why this story matters. GitHub is not merely updating a privacy screen. It is changing the default bargain for solo developers. Enterprise customers keep the protection of negotiated contracts. Individual users get a settings toggle, a month of notice, and a polished explanation about industry norms. That may be a rational business decision. It is also the sort of sentence that makes developers reach for the fine print with the enthusiasm of someone checking whether a “free” trial has already found their credit card.
What changed on April 24
GitHub announced the shift on March 25 in both a blog post and a changelog entry tied to updates in its Privacy Statement and Terms of Service. The effective date is April 24. From then on, if you use Copilot Free, Pro, or Pro+ and leave the setting on, GitHub may use your Copilot interactions to develop and train AI models.
GitHub says the setting already exists under Copilot privacy controls, and prior opt-out preferences carry over. If you previously disabled the old prompt-and-suggestion collection setting for product improvements, GitHub says your choice is preserved and your data will not suddenly jump the fence on April 24.
There are two exclusions that matter most. First, Copilot Business and Copilot Enterprise are not included in this training update. Second, GitHub says students and teachers who receive Copilot Pro for free are also not affected.
GitHub says real-world interaction data should make the models better. It also says Microsoft employee interaction data improved acceptance rates in multiple languages. You can believe that and still notice what changed in the bargain. The question is not whether training data helps. The question is who is now supplying it by default.
What code is in scope, and what is not
This is the part that deserves actual reading instead of screenshot-based panic.
GitHub says the data it may collect for training includes accepted or modified outputs, prompts sent to Copilot, code snippets shown to the model, code context around your cursor, comments and documentation you write, file names, repository structure, navigation patterns, and interactions with features such as chat or inline suggestions. In other words, not your entire development life, but certainly more than a single chat prompt and a polite nod.
The company also draws a deliberate line around private repositories at rest. GitHub says it does not use the stored contents of private repositories at rest to train AI models. But it also goes out of its way to explain why it used the phrase “at rest.” If you are actively using Copilot in a private repository, code snippets and associated context from that live session can still be part of the interaction data covered by this policy unless you opt out.
That distinction is subtle, but it is not trivial. “We are not training on your private repo” and “we may train on code Copilot sees while you use it in your private repo” are not the same sentence. One sounds like reassurance. The other is the actual contract.

There is another important carve-out in the FAQ. GitHub says it does not train on contents from any paid organization's repositories, even if someone is in that repo with a personal Copilot Free, Pro, or Pro+ subscription. It also says that if a GitHub account is a member of, or outside collaborator with, a paid organization, that user's interaction data is excluded from model training. Yes, the exception has subclauses. Privacy language loves a nesting doll.
GitHub also says the data may be shared with GitHub affiliates, including Microsoft, but not with third-party AI model providers for their own independent training. That last line matters, and it is one of the easier facts to lose once the discourse turns into everyone yelling “private code” at each other across three tabs.
Why developers reacted so hard
The HN and Reddit reaction was not really about discovering that AI companies enjoy more training data. Nobody needed a séance for that. It was about the asymmetry.
Business and Enterprise customers are protected because contracts say so. Individual developers are covered unless they find the setting and switch it off. The trust message there is hard to miss: organizations get negotiated boundaries; solo users get defaults. GitHub can reasonably argue that it is being transparent, and to its credit it did announce the change ahead of time, surface it in email, and preserve earlier opt-outs. But transparency is not the same thing as neutrality, and default settings are where product strategy stops pretending to be philosophy.
That is also why the wording around the toggle annoyed people. In the HN thread, several commenters fixated on the setting being framed like a feature you “have access to,” which landed less like a privacy control and more like a loyalty perk for donating your workflow traces. Nothing says trust quite like a consent screen that sounds as if it was workshopped by a growth team and a tax attorney.

I do not think the strongest critique here is “GitHub is evil now.” It is simpler than that. GitHub is redrawing the line between first-party value and user contribution, and the redraw falls hardest on the customers with the least contractual leverage.
What individual developers should do now
If you use Copilot on a personal account and you do not want your interaction data used for model training, go to github.com/settings/copilot/features, open the Privacy section, and disable the training setting before April 24. If you already opted out under the older data-collection control, GitHub says you do not need to do anything.
The broader market lesson is harder to ignore. Coding assistants are no longer just fighting over raw model quality. They are fighting over workflow position, billing boundaries, and access to real developer interaction data. We are seeing the same control instincts elsewhere in the market, whether through the rise of orchestration layers in AI coding's new bottleneck: agent orchestration, or through first-party vendors tightening the edges of third-party access as in Anthropic clamps down on Claude OAuth wrappers. The model is only part of the moat. The default settings are part of it too.
That is why this Copilot change feels bigger than one checkbox. It tells you where the coding-agent market thinks future advantage comes from: not just better weights, but better access to the messy trail real developers leave behind while they work.
If you are fine making that trade, leave the setting on. If you are not, turn it off. But either way, it is worth seeing the change clearly. GitHub did not just improve a product. It changed the deal.
Source file
Public source trail
These links anchor the package to the underlying reporting trail. They are not a substitute for judgment, but they do show where the reporting starts.
Core announcement covering the April 24 effective date, affected plans, included interaction data, opt-out path, and explicit exclusions.
Formal policy and terms framing, including the line between active interaction data and private repositories at rest.
FAQ thread with the important carve-outs on students and teachers, enterprise-owned repositories, and paid-organization exclusions.
Useful reaction signal showing why the framing and default-toggle language landed badly with many developers. Not a source of record for policy.
Spillover discussion around opt-out settings and the individual-user impact. Context only.
Preserves the user-facing email copy and the opt-out discussion context. Context only.

About the author
Talia Reed
Talia reports on product surfaces, developer tools, platform shifts, category shifts, and the distribution choices that determine whether AI features become durable workflows. She looks for the moment where a launch stops being a demo and becomes an ecosystem move.
- 34
- Apr 1, 2026
- New York
Archive signal
Reporting lens: Distribution is usually the story hiding inside the launch.. Signature: A feature matters when it changes someone else’s roadmap.
Article details
- Category
- AI Tools
- Last updated
- April 11, 2026
- Public sources
- 6 linked source notes
Byline
Covers product surfaces, tools, and the adoption moves that turn AI features into durable habits.




