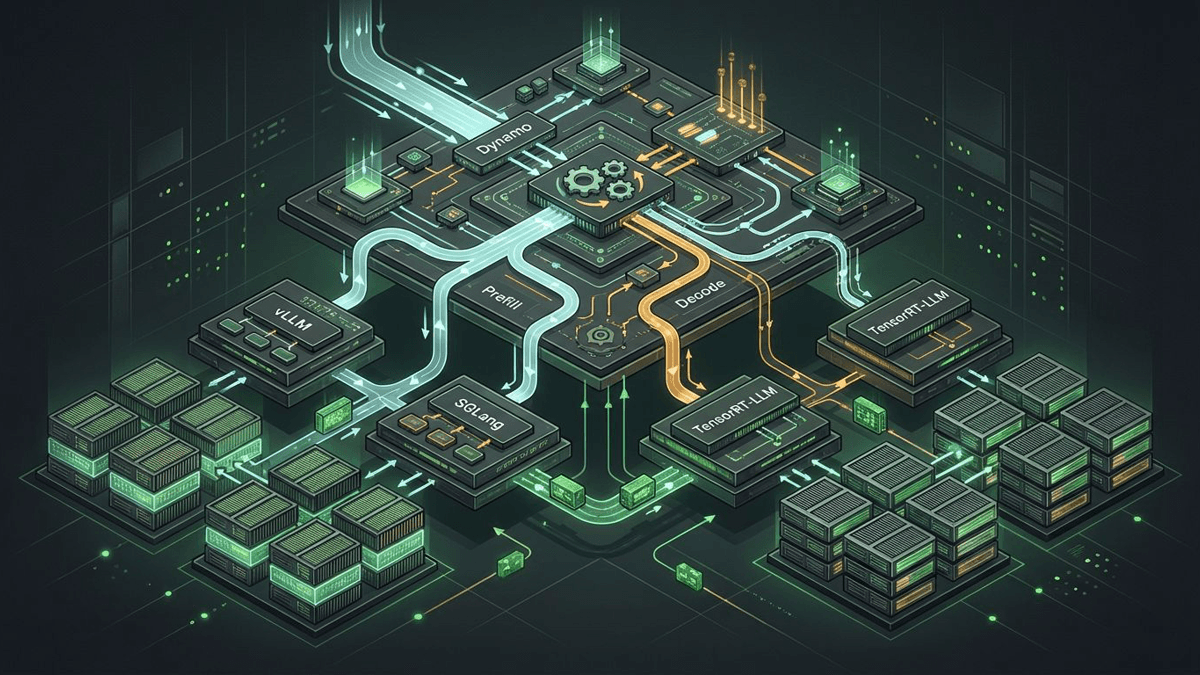
NVIDIA Dynamo is the orchestration layer above vLLM
NVIDIA Dynamo matters because it sits above vLLM, SGLang, and TensorRT-LLM to coordinate routing, KV reuse, disaggregated serving, and scaling across GPU fleets.
 AI News SiloCuration Over ChaosAI News SiloCuration Over ChaosAI News Silo organizes the latest AI news articles about everything in artificial intelligence today.
AI News SiloCuration Over ChaosAI News SiloCuration Over ChaosAI News Silo organizes the latest AI news articles about everything in artificial intelligence today.AI News Silo organizes the latest AI news articles about everything in artificial intelligence today.
Category archive
Follow AI Infrastructure coverage across chips, inference economics, model serving, and the cost disciplines that decide what can actually scale.
Why this category exists
AI Infrastructure coverage from AI News Silo, tracking inference economics, GPU costs, model serving, chips, and the operational stack beneath the headline cycle.
High-signal themes
Core search targets: AI infrastructure news, AI infrastructure analysis, LLM inference.
NVIDIA Dynamo matters because it sits above vLLM, SGLang, and TensorRT-LLM to coordinate routing, KV reuse, disaggregated serving, and scaling across GPU fleets.
vLLM 0.18.0 signals a split multimodal serving stack, with render, transport, and GPU inference starting to separate into cleaner infrastructure tiers.
FlashAttention-4 shows Blackwell-era AI economics will be shaped by attention kernel optimization and non-tensor bottlenecks, not FLOPs headlines alone.
Meta's MTIA roadmap and its 6GW AMD pact point to the same goal: cheaper inference, more control, and less life spent waiting on one supplier's clock.
NVIDIA's AI grid pitch is a bet that telecom networks can sell distributed inference, but only if operators package it like a product and not a committee.